Data Hub 10.2 on-premises release notes
Released Aug 2023
Data Hub enhancements
New UI default
The new UI introduced in 10.0 now becomes the default interface for Data Hub. You will still be able to navigate back to the old UI temporarily should you require this, but this change will assist our phase-out transition of the old UI, as we are preparing to deprecate it in a future release.
 |
Environment settings visible in the title bar
From the profile icon in the top right of the title bar, users can choose to set a Working Date or Run as a different user.
When setting a Working Date, or Run as a different user, Data Hub will now display the setting in the right-hand side of the title bar.
 |
 |
Modeling enhancements
Processing flexibility and diagnosability
Model process history
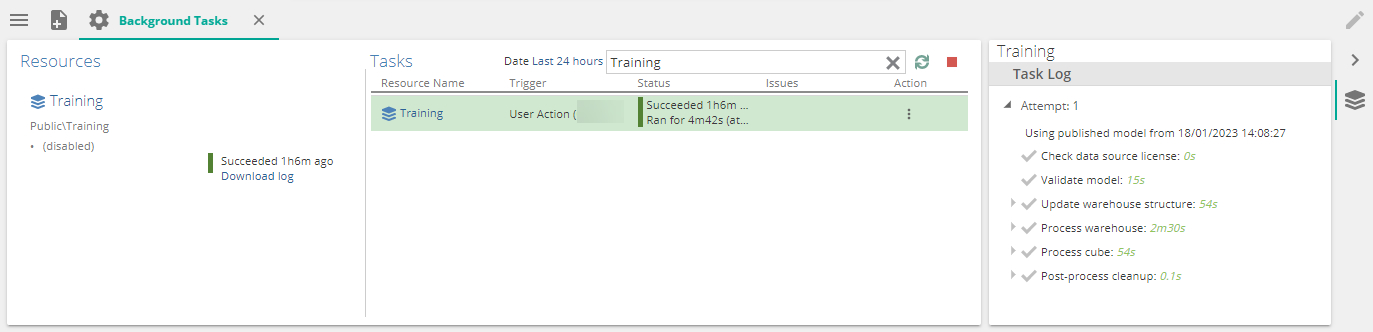
While processing a model, the progress has always been visible on the model properties panel while processing. Once the processing has completed the progress tree isn't available anymore.
A new addition has been made to the background task screen. A Model task log is now available on each model process task, while running but also as history, so it can be revisited at any time.
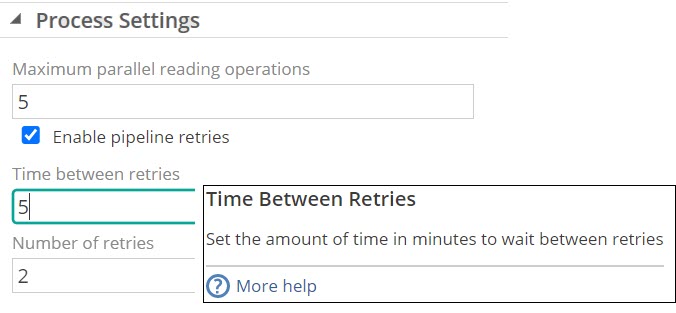
Pipeline retries for duplicates
Configurable data source migration retries during model processing were further enhanced to also include retrying when duplicate key exceptions are experienced.
 |
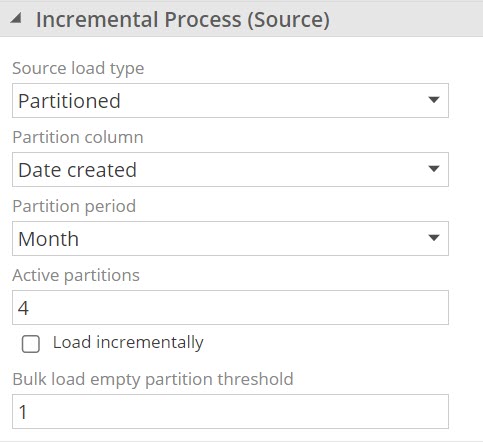
Partitioned pipeline processing
Processing selected amounts of source data has become increasingly important for customers with large data sets. An exciting enhancement has been added to assist in configuring subsets of source data to migrate.
Partitioned pipeline processing provides the ability to migrate only periods of active source information based on date partitions, using a suitable date column, instead or reloading a full data set.
For example a large transaction table can be set to a Partition period of Month, and Active partitions of 4 which will process all data for the four months leading up to the current date, including the month of the current date. If current date is 15 June, all data from 1 March to 15 June will be migrated. Detailed information here
Configuration for this feature can be set in the Incremental Process (Source) section of individual pipelines.
 |
Important
It is important to note that the Partition column's data cannot change, as it will cause partitioned processing to fail.
Partitioned processing, loading incrementally.
It is also possible to combine partitioned processing with incremental loading. When Load incrementally is enabled, only changes and additions will be migrated across the active partitions. Historic partitions will be untouched.
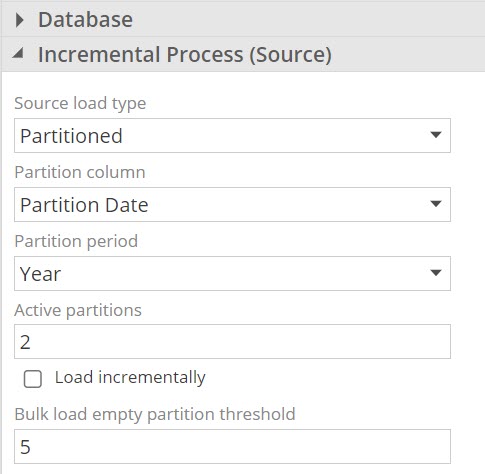
Configurable historical partition threshold
Configure Empty Bulk Historical threshold: Sparsely distributed data may pre-emptively trigger the bulk historical partition, particularly when partitions are configured to be a day in size. This setting raises the threshold for a bulk load from the default single empty partition.
 |
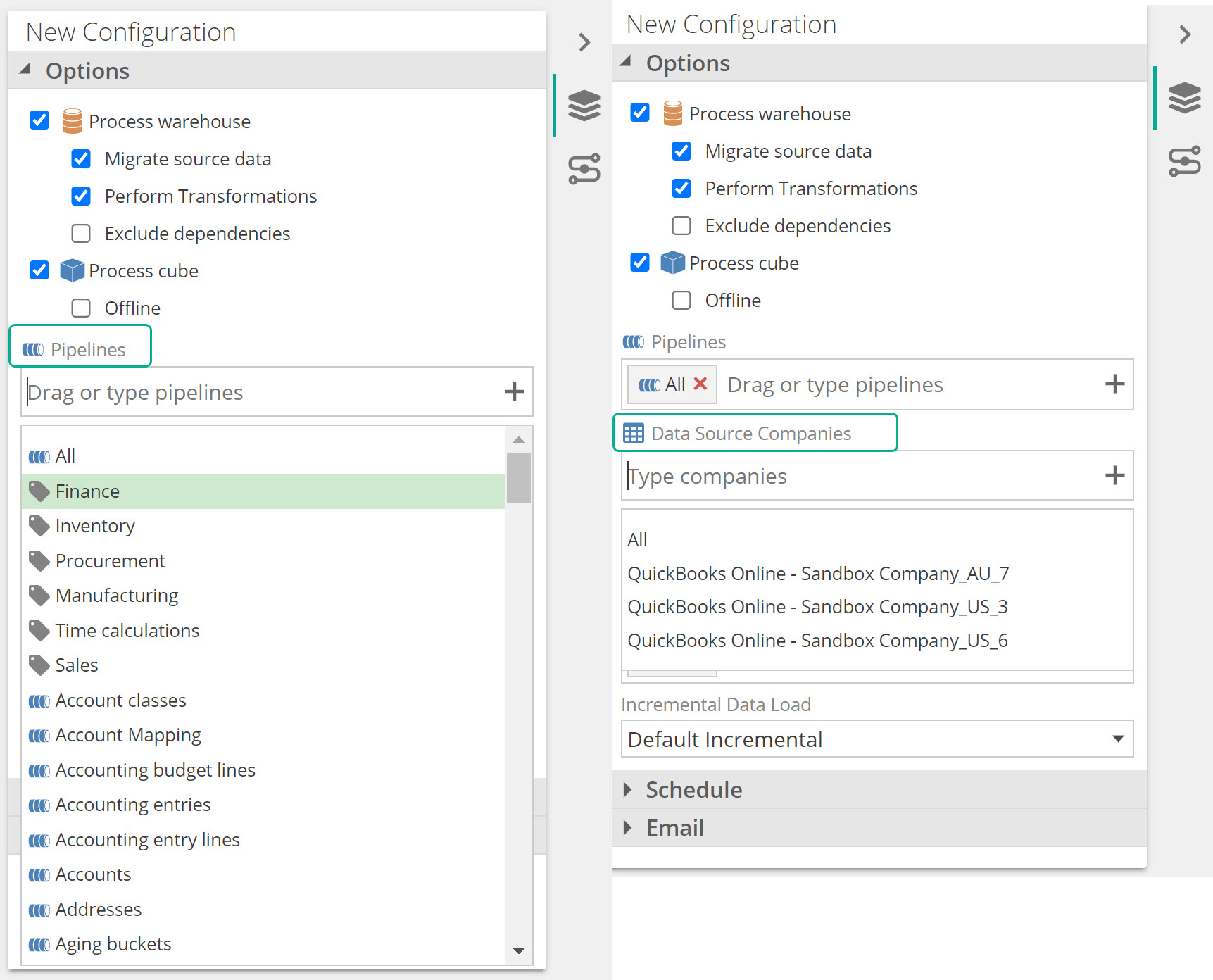
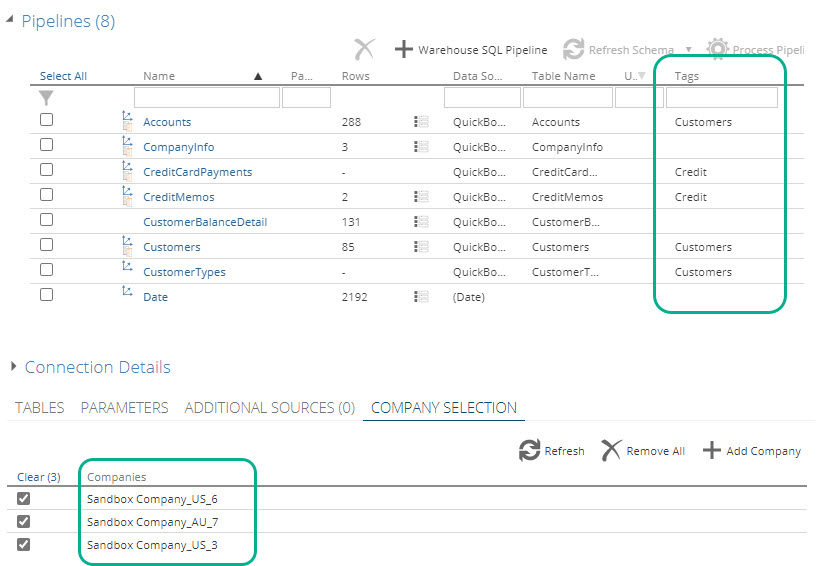
Processing per Company or per Tag
Per company and per tagged pipelines processing are new additions to model processing. It gives users the ability to process their models only for a specified company or group of tagged pipelines within the Data model, and not necessarily processing the entire model.
Pipeline tagging is achieved by adding labels in the tags column on the model screen pipeline grid, to logically group pipelines together. More information about Modules and tags
This feature becomes very useful to organizations that have several companies and/or large data sets. The enhancement can impact performance positively by reducing the amount of data to refresh, and therefore reduce processing time and removing data that is not required at any given point in time. Detailed information can be found in Processing parts of a model.
Process per company and process per tag have also been incorporated in a new version of the Model Process API
Both these new settings are available in two areas:
- A new Data Source Companies input text box, and new Tag items in the Pipelines dropdown, on the model process pop screen..
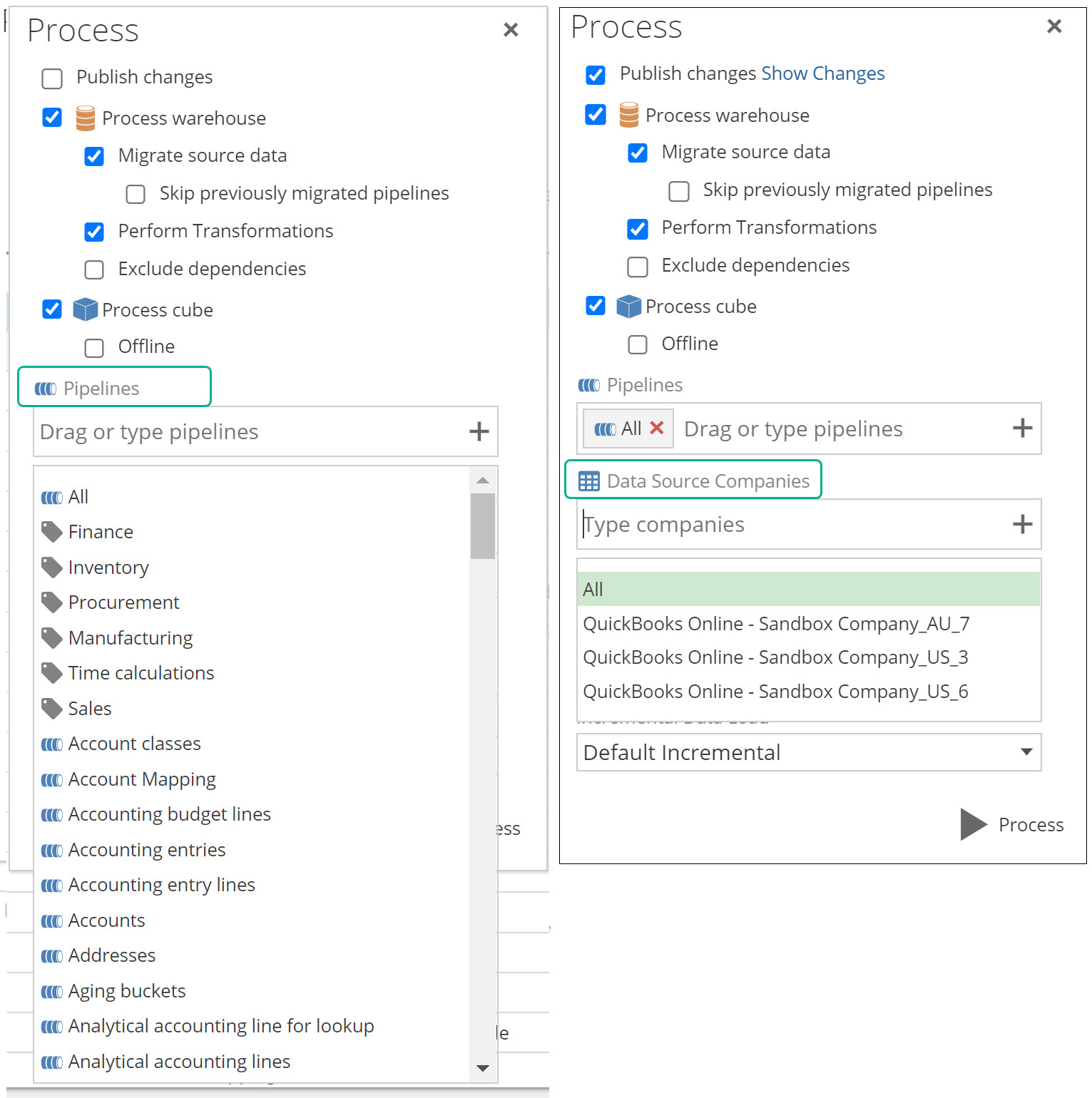
The process configuration setup panel.
Note
The Data Source Companies dropdown will be greyed out, if the data model does not use at least one datasource that supports a COMPANY SELECTION tab.
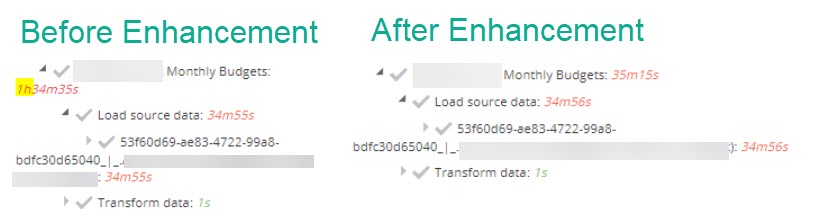
Pipeline processing times enhancement
During processing, relying on dependencies sometimes inflated processing times and it wasn't clear how efficient the processing of individual pipelines was.
Wait times for dependencies are now excluded from pipelines processing time calculations, so users can gain a more accurate understanding of the actual processing times and a clearer picture of the efficiency or potential bottlenecks.
 |
Modeling UI and UX enhancements
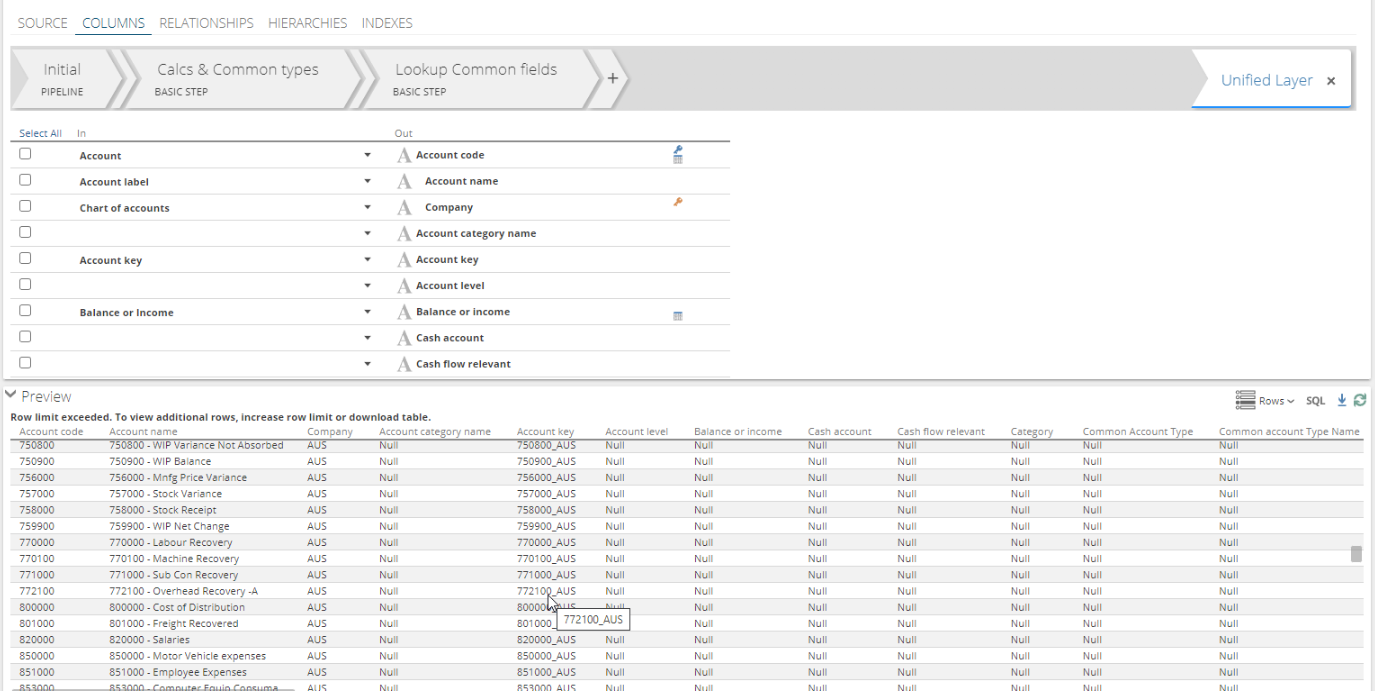
Pipeline preview pane freeze columns
The ability to freeze the column headers on the preview pane has been added.
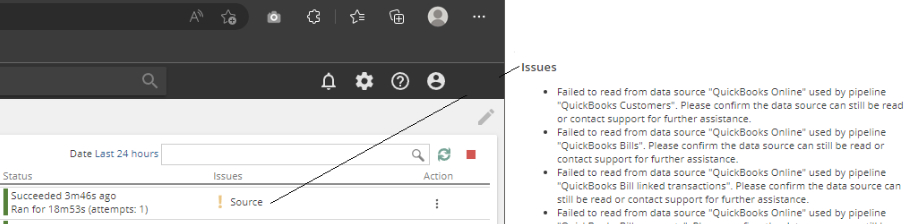
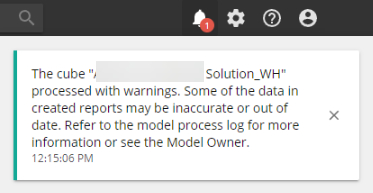
New in-app alerts for Model health
Notifications for model processing warnings have been improved. Process warnings and errors can be seen in the background tasks and when analytics are opened that connect to a cube that has processing warnings, a relevant notification will be shown on the alerts icon.
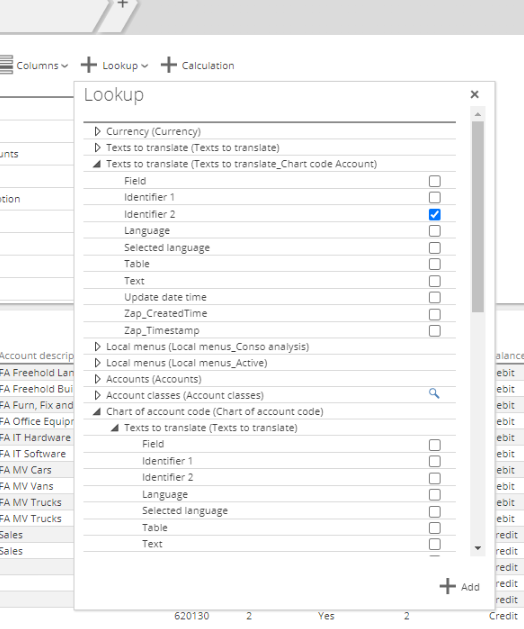
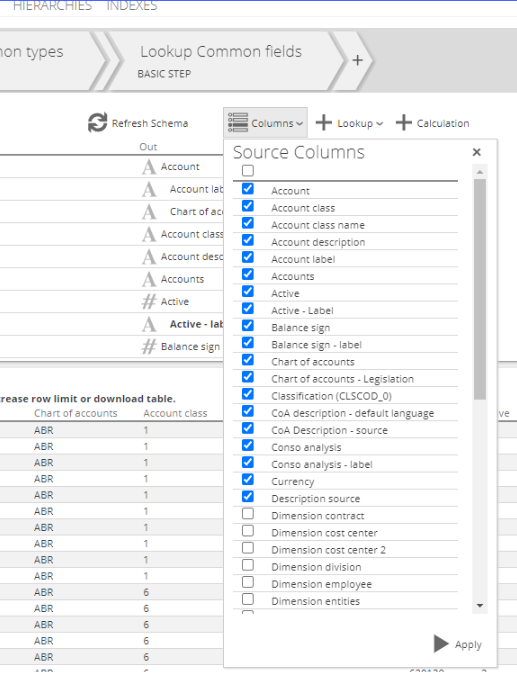
User Interface enhancements in Column and Lookup dropdowns on pipelines
Inside the Column and Lookup dropdowns on pipelines, the respective Apply and Add buttons have been moved outside the scrollable area, so that it is always visible.
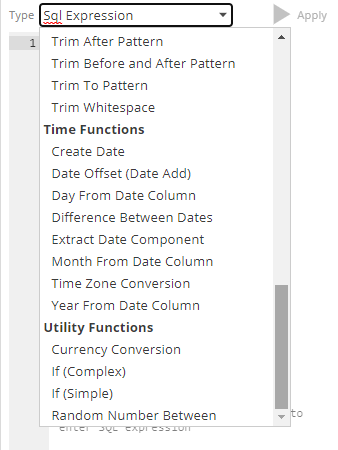
New SQL Expression Category
A new sql expression category Utility Functions was added for improved grouping and organization of functions.
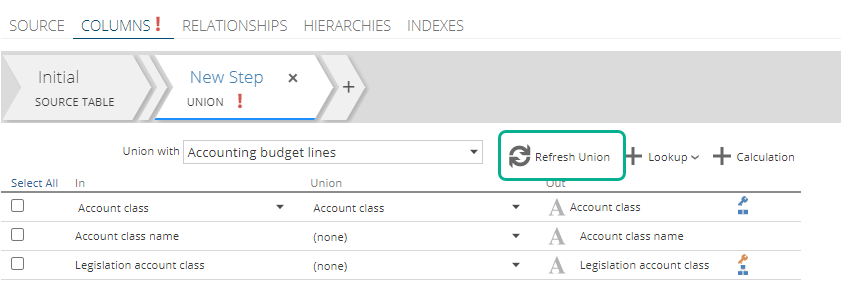
Union Step enhancement
Previously the only way to refresh the table list on a union step, was to use the refresh schema button on the Initial step.
A new Refresh Union button has been added to the union step to refresh the schema of only the unioned tables.
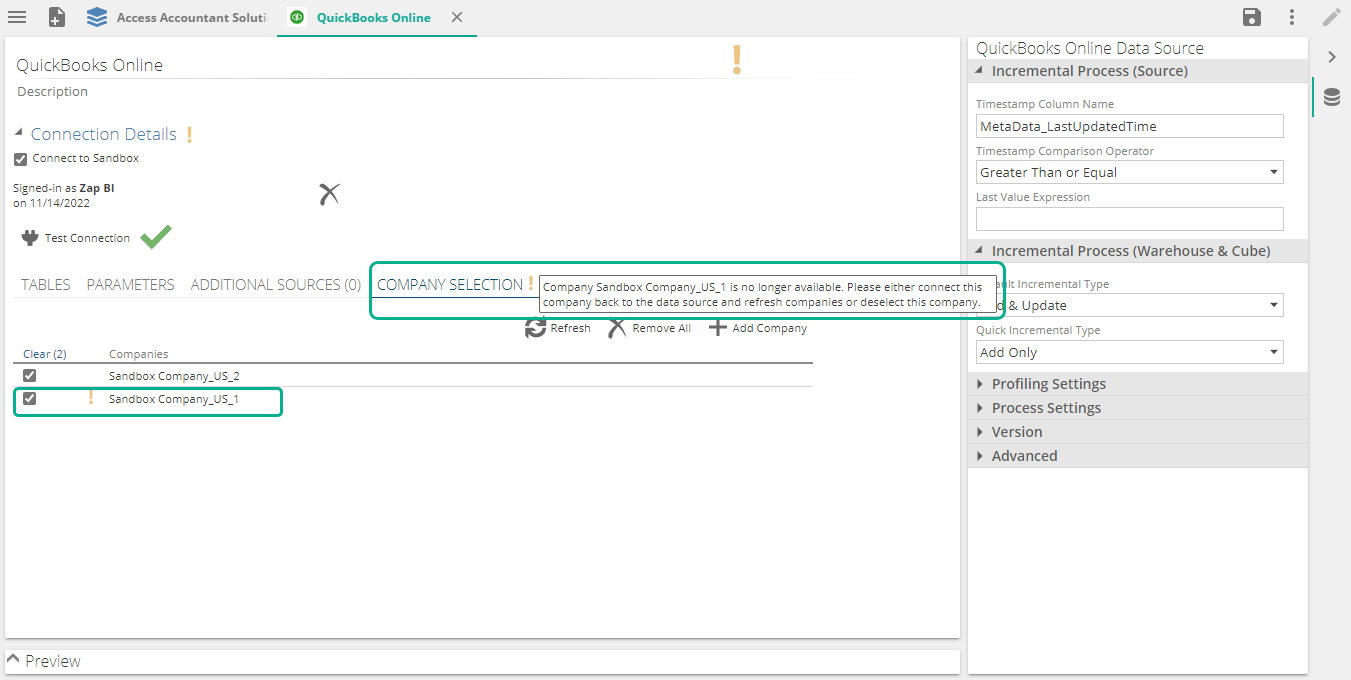
Data source company selection change of behavior
When previously selected companies in a data source becomes unavailable or disconnected, it will now show a validation warning for improved awareness.
Primary company setting
Marking a company as a primary company is being removed from the following data sources:
Xero
MYOB AccountRight
MYOB Essentials
QuickBooks Online
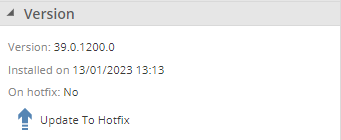
Datasource last updated
The date the datasource was last updated is now visible in the version section of the datasource properties panel.
Copy-paste text from resource property screen
All fields on the resource properties screen are selectable as appropriate.
 |
Background Tasks now include date and time
Background tasks now shows a more helpful date and time of actual execution.
 |
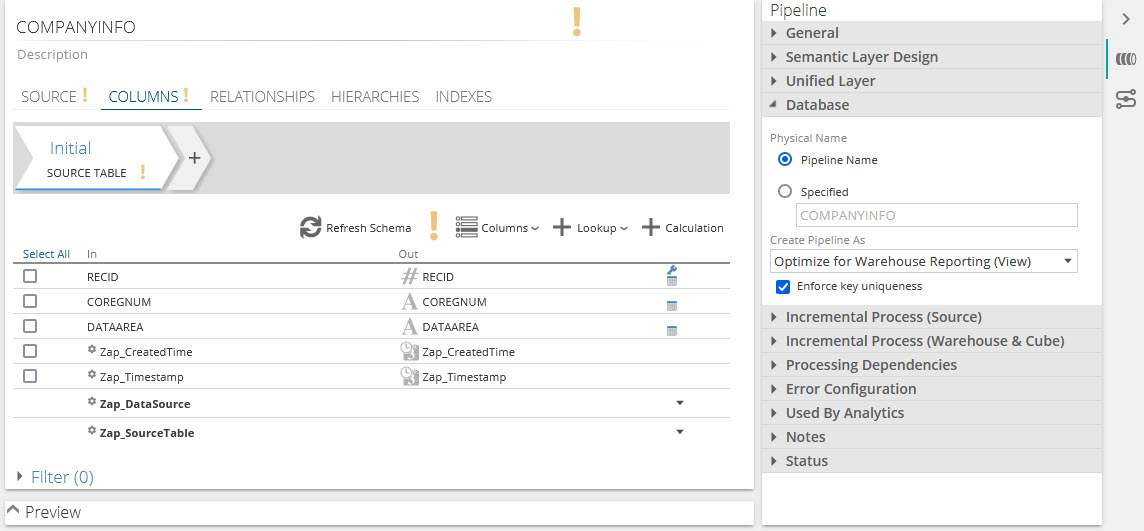
Pipeline and Column Name improvements
Pipeline and column physical name behavior has been improved. Datasources like Dynamics, SAP, SYSPRO and Sage that provide captions for table and column names in the source.

In the past, pipeline and column physical names were derived from the table name.
 |
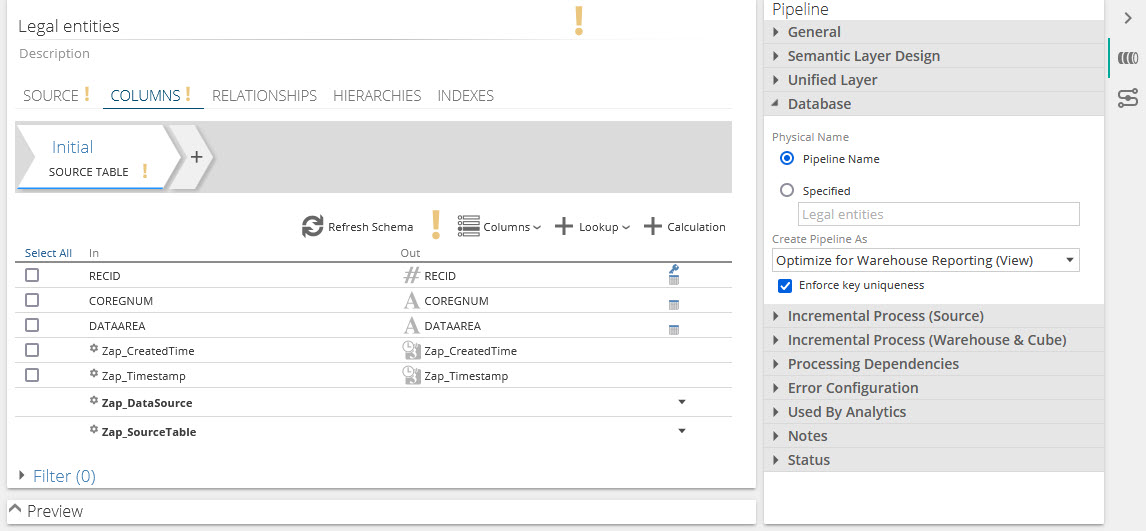
The changed behavior will now default to using the caption for the physical name if it is available.
 |
New Datasource connectors
Excel Online
A new Excel Online connector has been introduced. The connector uses Azure AD authentication to connect to a SharePoint site. It reads and can digest all excel workbooks on a given SharePoint site or document directory.
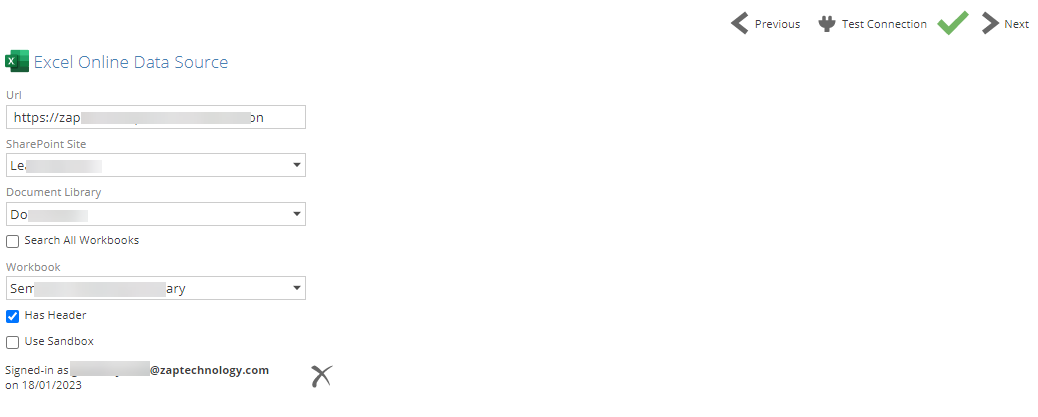
Existing Datasource connector enhancements
Sage 100 improvements
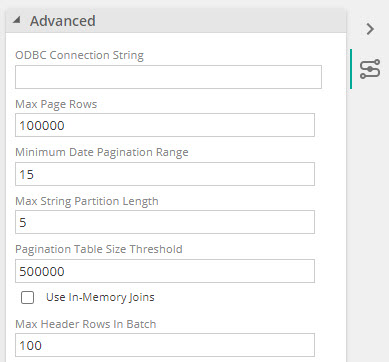
Performance: When using the 64bit ODBC driver, slow performance and crashing of the driver can occur when a result set returned is too large. A pagination strategy has been implemented to improve this by allowing configuration of the following settings. Read more about the strategy here
A full load: is attempted for each table, if the number of rows are below the Pagination Table Size Threshold.
Date pagination: Configure a date range for data extraction data.
String pagination: Using string columns to Partition data.
Performance fallback: In-Memory Joins can be configured as a fallback strategy
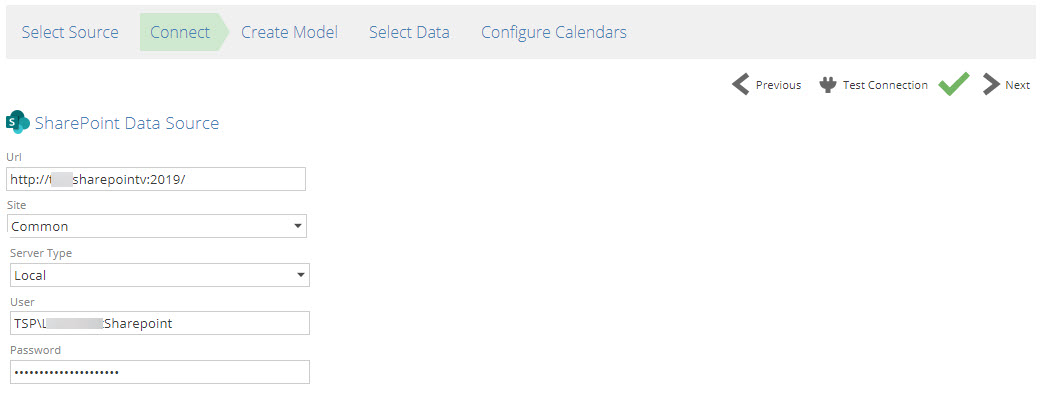
SharePoint
Support for SharePoint On-prem with Windows authentication has been added.
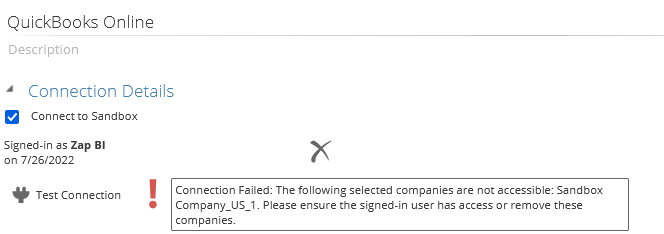
Quick books Online
Test connection enhancements – the Warning/Error icon now shows a tooltip which provides better information about company connections in error (e.g. loss of authentication token)
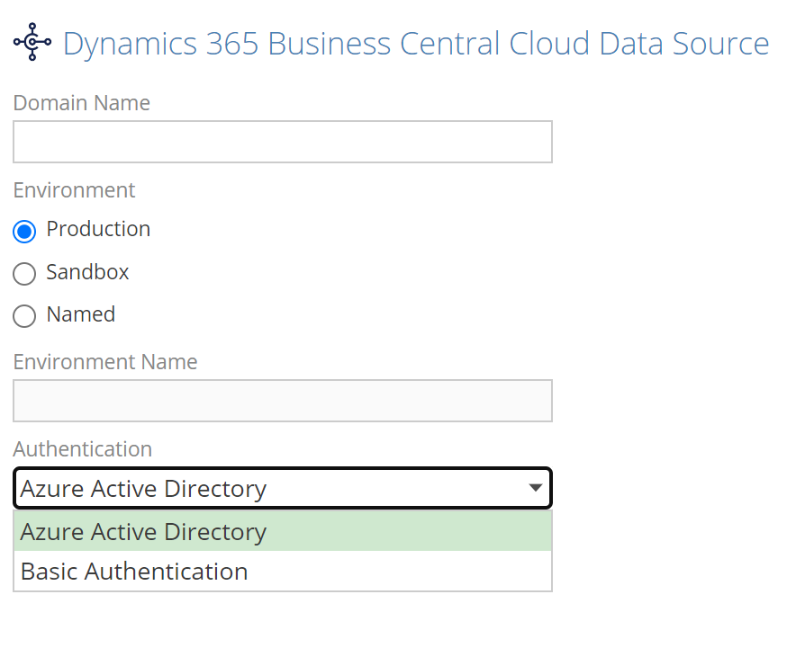
Business Central Cloud
In order to improve security, the option to authenticate to webservices using a Webservice API key has now been deprecated in sandbox environments. Only Azure Active Directory should be used.
 |
SAP SQL source
For incremental source loading to work accurately we need a column that is always:
Populated
Updated for each change
When either or neither of these requirements are met, it causes inaccuracies.
An improvement was made in the Incremental Load date column logic to ensure the requirements are always met.
When UpdateDate is null, but CreatedDate exists, we use CreatedDate.
When UpdateDate is null, and CreatedDate DOES NOT exist, we use getdate().
Odata Dataverse
Microsoft Dataverse can now be accessed using ZAP’s OData connector as all data in Dataverse is stored within the OData specification.
Dataverse requires Azure Active Directory authentication. Instructions will be available to guide you through the authentication registration.
REST additional Authentication
PKCE has been added as an additional authentication method for REST. More information on PKCE
Odata Authentication improvements
Odata authentication types supported have been expanded to include the following:
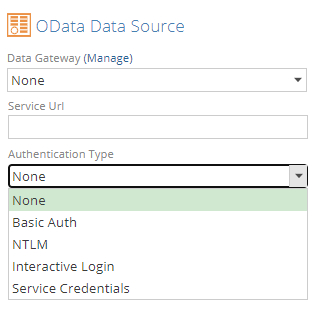
Basic Auth
NTLM
OAuth
Service Credentials
Analytics enhancements
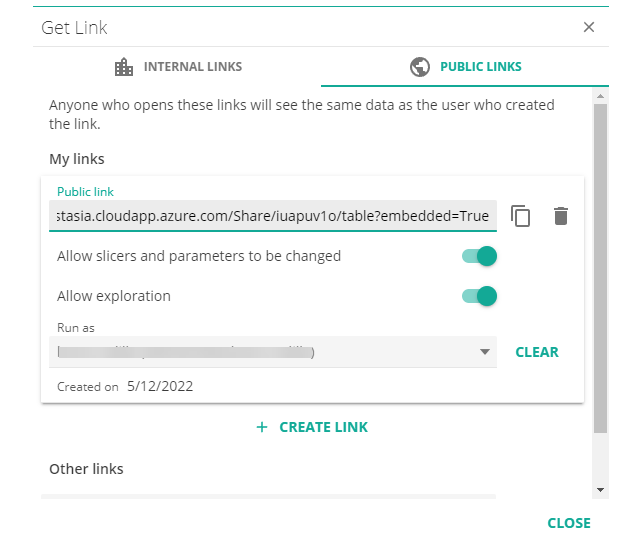
Get Link improvements
With this new enhancement, recipients of public links are able to interact with the data by drilling up, down and through, if the link was published with this permission integrated.
When the user's role creating the public link, have the explore permission they will be able to enable or disable the Allow exploration and Allow slicers and parameters to be changed permission on each individual public link they create.
Read more here
 |
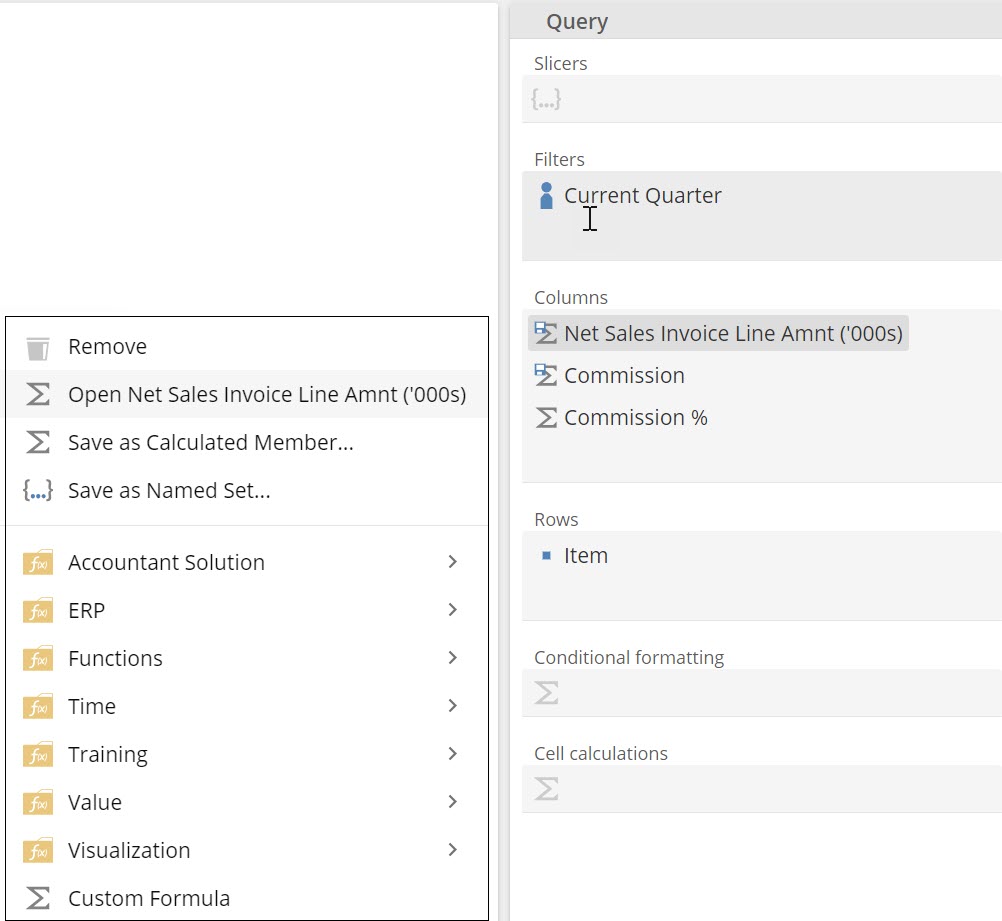
Query design - New double click shortcuts
To open a Calculated Member or Named Set previously, you had to right click and then choose open. Double click has now been added as a new short cut.
 |
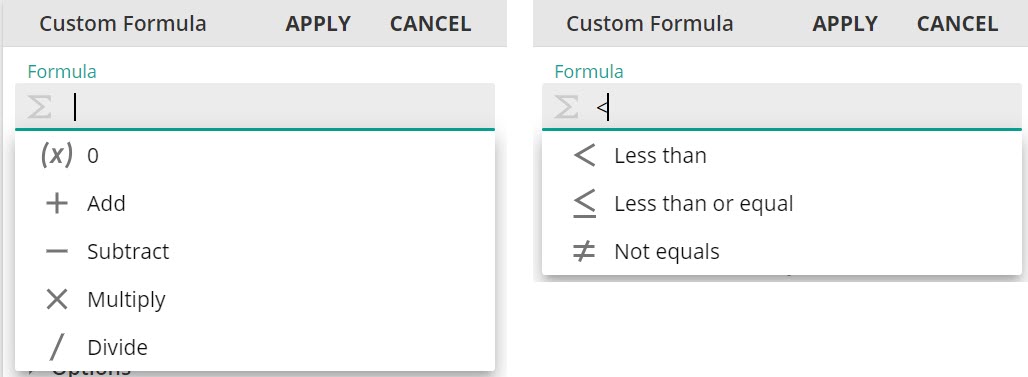
Formula design - New shortcutsfor adding operators
Users now have the ability to add operator functions with space as well as enter. The new space functionality only works with operator functions symbols. Type your operator and pressing space, will add it to the placeholder.
 |
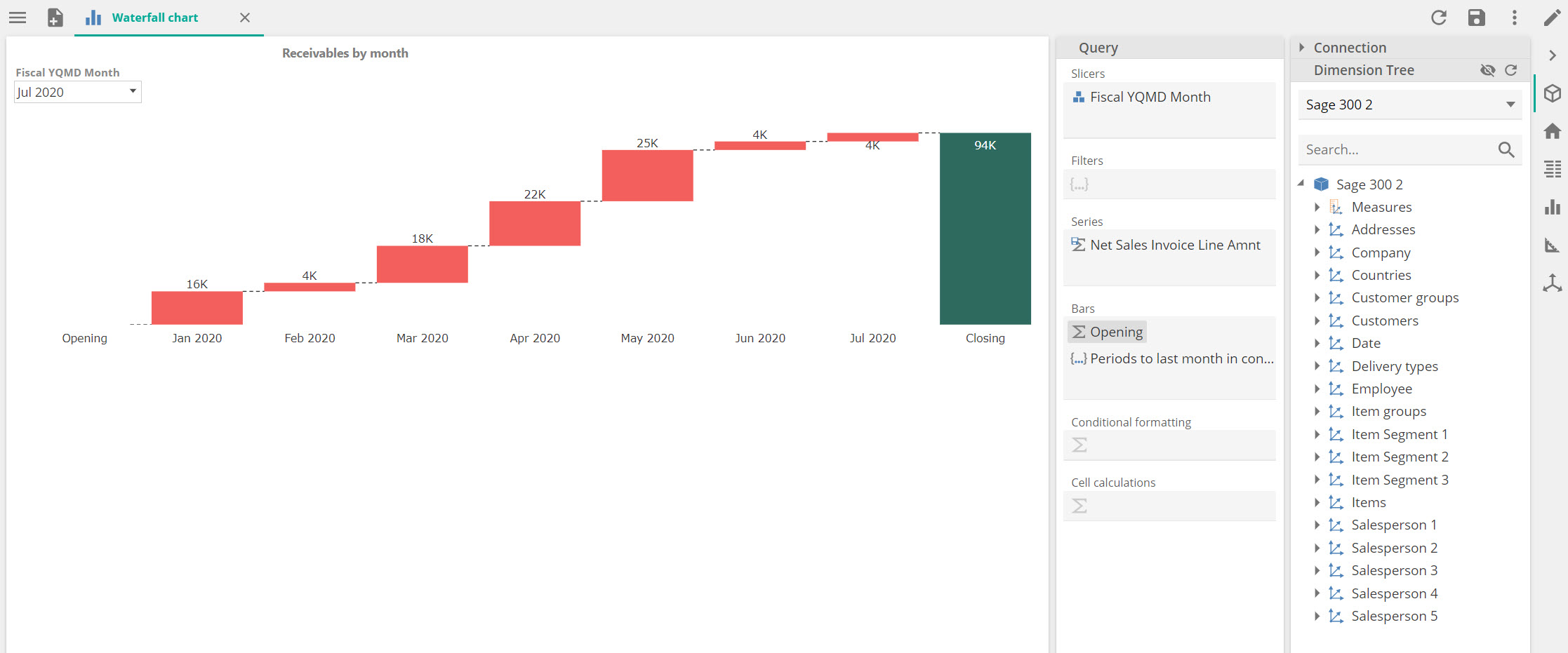
Waterfall chart improvements
The new improvements allow users to add custom formulas or calculated members to the chart, and these will be included in the TTD calculation. It is also helpful when adjustments need to be incorporated.
Model Process API
A new version of the Data Model Process API has been released. Its main functionality is still to process a model, but has been enhanced to accept additional parameters to further fine tune the HTTP requests.
Two parameters in particular to take note of:
Process a subset of companies.
Process a subset of pipelines by using tags
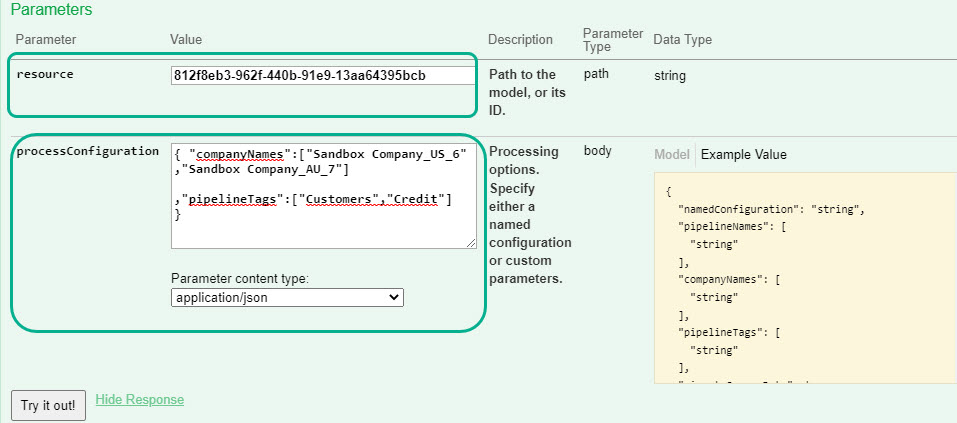
A new interface has also been made available to facilitate building, easy testing and provide detailed, technical documentation about the API. Read more about How to use the API
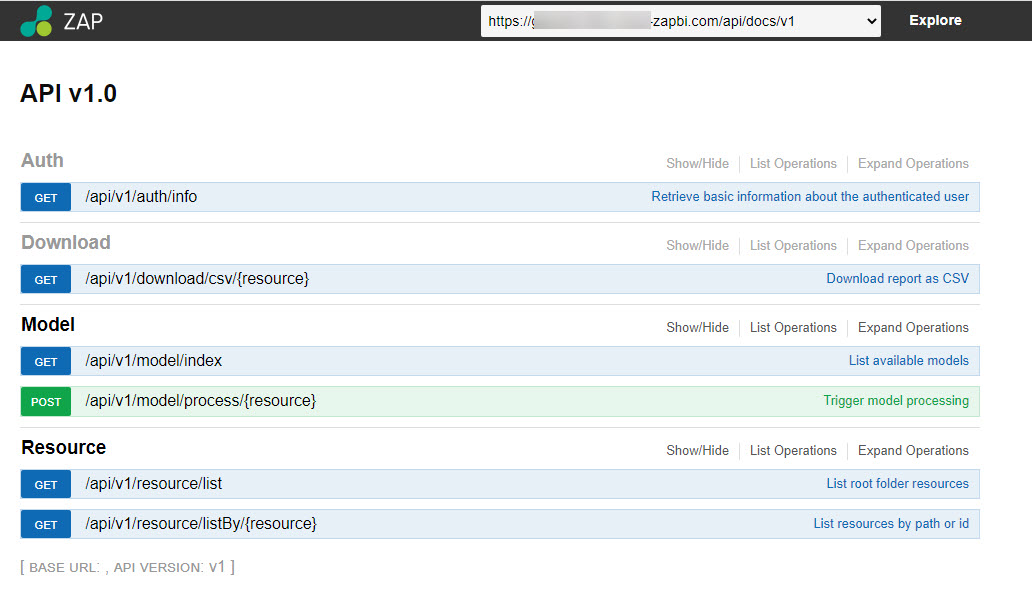
Note
The legacy Model Process API is still available. Legacy Model Process API
Deprecated features
Sage 300 Optional field columns
These are no longer split into individual columns in Sage300 optional field tables. Usages of these columns should be converted to use the optional field columns on the relevant primary table.
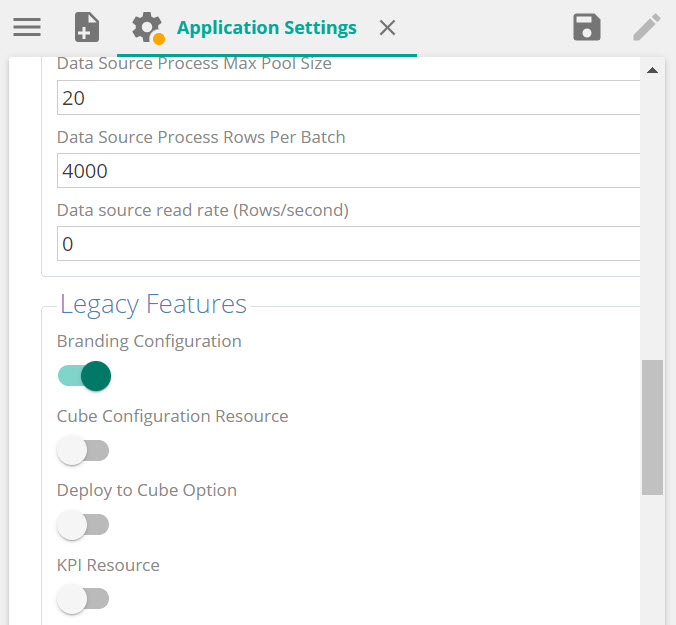
Branding settings
Branding configuration has been deprecated into Legacy features. It can still be used and configured but have to first be enabled by a system administrator under legacy features from the Application Settings menu.
 |