Pipelines
Overview
Pipelines are configurable resources that exist within models. They define a source, steps that transform the data, and a destination. Pipelines are where most model customization occurs and most of this configuration focuses on the pipeline’s column list.
Transforms are performed by adding additional transform steps. Pipelines also capture other configuration options such relationships to other pipelines. Manipulating or transforming the source data into the desired form for creating a cube is done by adding steps to pipelines and changing pipeline settings.
The Pipelines list on the model tab displays all pipelines from all data sources in one, single list. Click an individual pipeline to view its contents in a separate tab.
Pipeline types
Pipelines can be categorized by how they source their input data. There are two aspects to this:
Source Origin. The pipeline may source its data from a table in an external database or API source. Alternatively, the pipeline may get its input from the output of another pipeline in the data warehouse.
Source Type. The pipeline may get its input from a single table or pipeline (a pipeline may be thought of as a table in the data warehouse). Alternatively, the pipeline may use an SQL statement to bring in data from multiple tables or pipelines.
Type | |||
Single Table | SQL | ||
Origin | Data Source | Source Table Pipeline | Source SQL Pipeline |
Warehouse | Warehouse Pipeline | Warehouse SQL Pipeline | |
Manual Entry | Data Entry Pipeline | ||
Note
Only data sources that support SQL queries (most API sources do not) allow the creation of SQL pipelines.
Source pipelines
Source table pipelines. Source table pipelines take input from a single source data table.
Source SQL pipelines. Source SQL Pipelines let you specify an SQL statement, that provides the input to a pipeline from multiple source tables in the same source database.
Warehouse pipelines
Warehouse pipelines. Warehouse pipelines take input from other pipelines in the warehouse. Input may be needed when an intermediate result from one pipeline is needed in the cube and the data must be further processed in another pipeline to be separately included in the cube.
Warehouse SQL pipelines. Warehouse SQL Pipelines may be used when tables are inserted into the data warehouse using a product such as SQL Server Integration Services (SSIS).
Note
Source SQL Pipelines and Warehouse SQL Pipelines should be used minimally to best validate your model.
Important
Do not confuse warehouse SQL pipelines with source SQL pipelines. Warehouse SQL pipelines allow you to write SQL against other pipelines in the warehouse. Source SQL pipelines allow you to write SQL against tables in a data source.
The SQL in a Warehouse SQL pipeline is executed against the data warehouse in the context of the user specified in the model server. Although the SQL is validated by Data Hub, this validation is not exhaustive. It is recommended that you adopt good development practices and perform tests on models containing Warehouse SQL pipelines in a development environment before deploying to the production environment.
Data Entry pipelines
Data Entry pipelines give users the ability to create pipelines where they can insert and interact with data manually. Data is added manually by typing or copying and pasting.
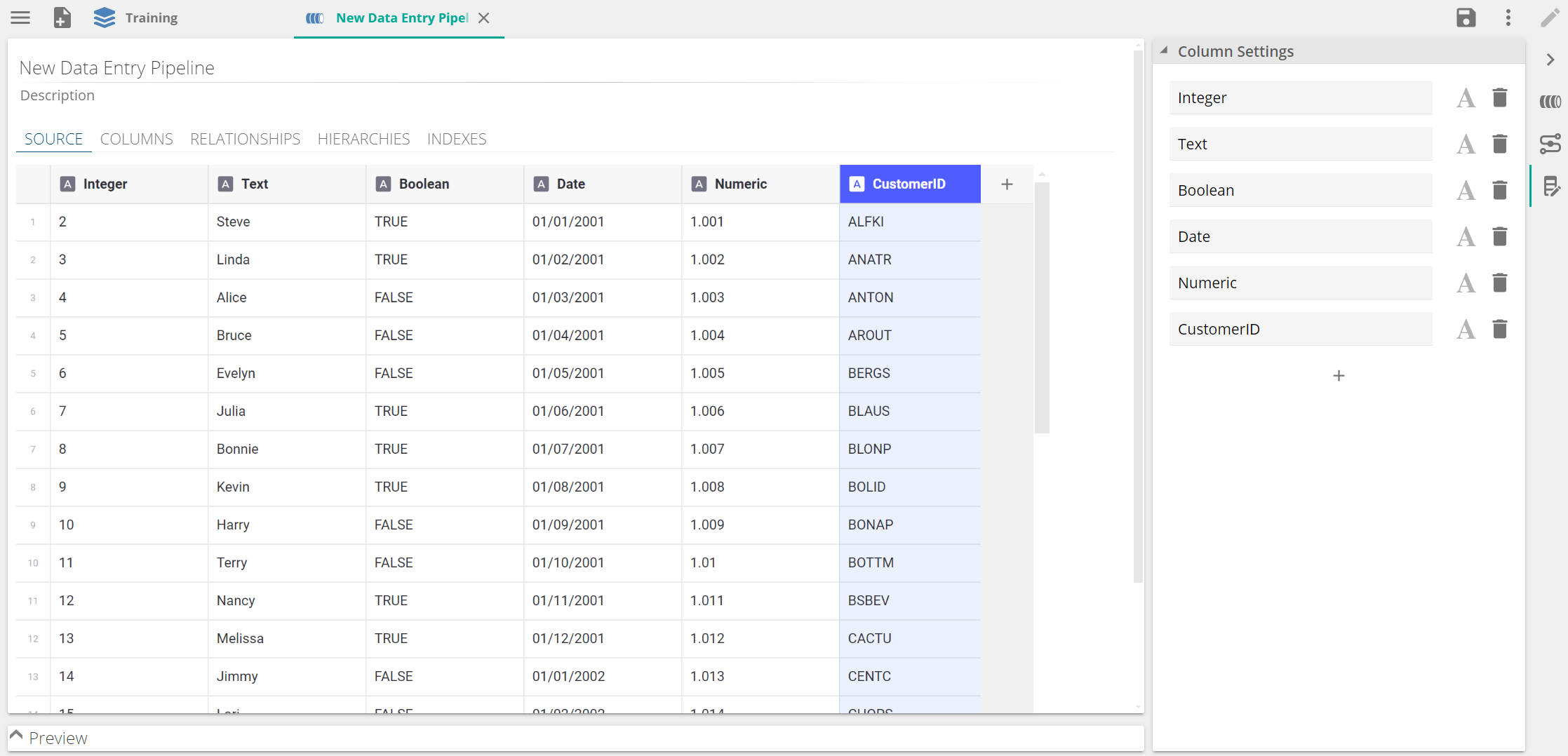 |
Data type validation
When data is entered, data type validation will highlight any incorrect values.
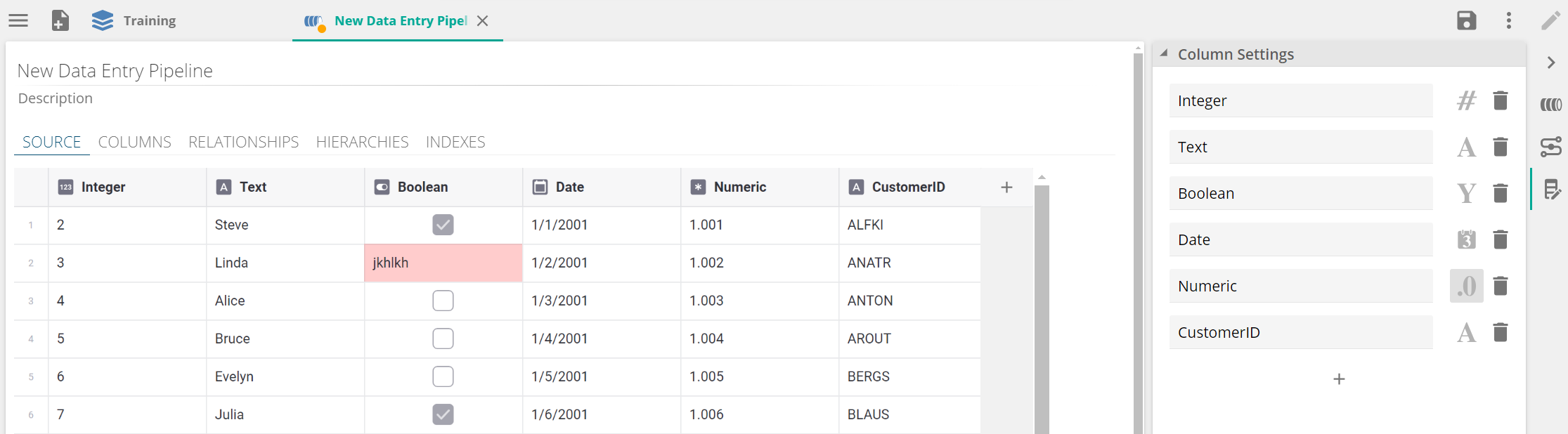 |
Note
Only two date formats are currently supported as valid date types: mm/dd/yyyy and dd/mm/yyyy
Date validation is done based on a user's date and time locale.
Any non date or empty date values are highlighted as invalid.
Example based on an Australian date locale
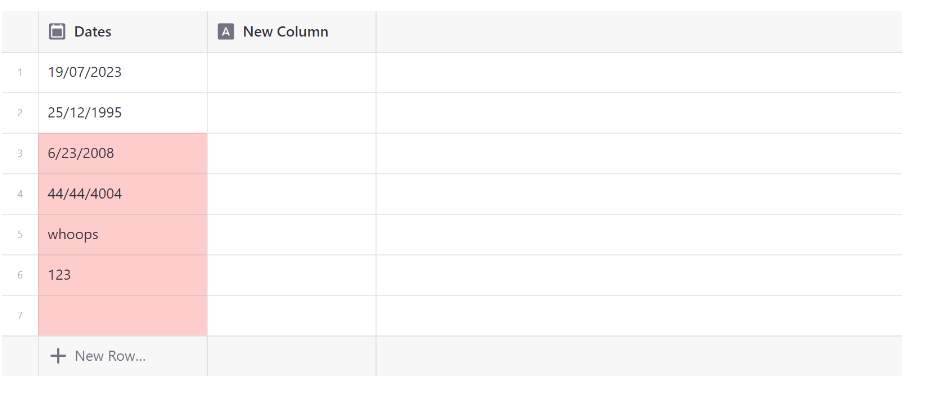
Data Entry grid settings
Change the data types
Add additional columns to your dataset
Rename column names
 |
Data Entry incremental processing
Incremental processing is available for data entry pipelines. Timestamp columns created on data entry provides the date columns needed for incremental processing
Important
In order to enable incremental processing, ensure your data entry pipeline has a primary key enabled. Without this the pipeline will process a full refresh every time.
 |
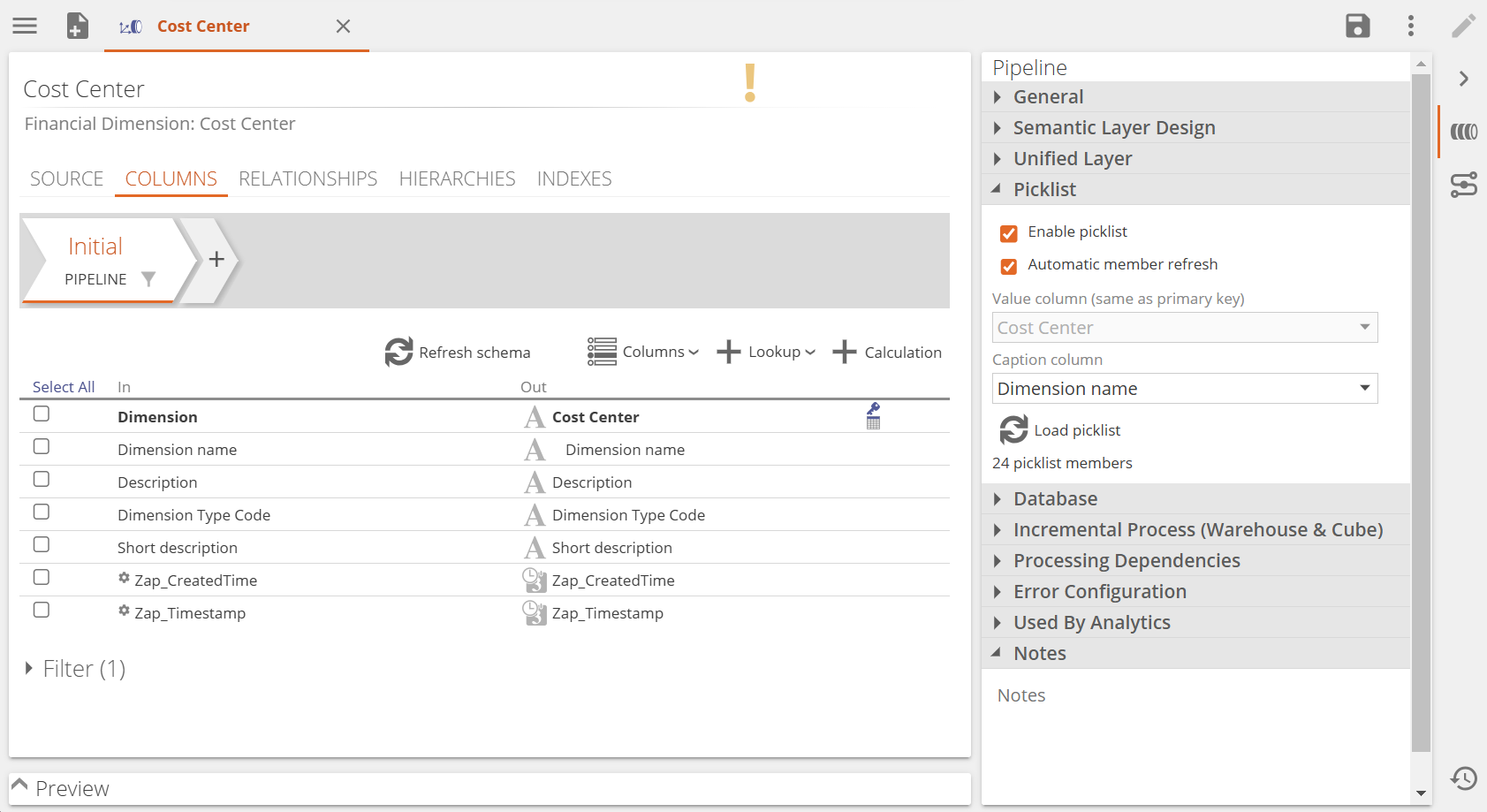
Using picklists
Picklists allow users to turn the data in existing pipelines into picklists, for use in the Data Entry pipeline.
Enable the Picklist function in the Pipeline panel on any pipeline, and specify the value and caption columns.
Note
Picklists are limited to 100 values.
 |
To use the picklist in the data entry pipeline
Add a column in the Data entry column settings panel
Change the data type to picklist
Use the dropdown in the data grid to assign picklist values

Pipeline profiling
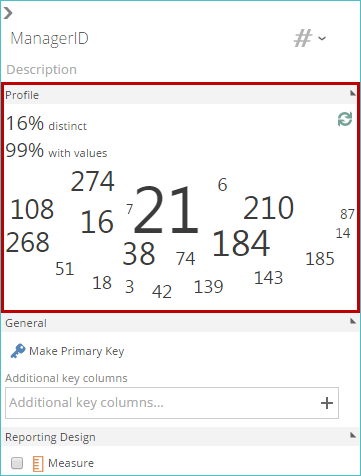
When a pipeline is added to the model, it is automatically profiled. Profiling analyses the source table's structure and a sample of its data in order to determine the best default settings for the pipeline and its columns. This information is then displayed in the Profile area of a column's Design panel.
 |
The sample data is also available for viewing in the Preview panel.
Profiling provides more information than can be obtained from the data source's metadata, improving the ability to make informed decisions about the data.
The following information is generated by profiling:
The data type of each column. This information is particularly useful for data sources that don't have types stored in metadata, such as Excel and CSV files.
The granularity of each column. This information appears as the percentage of distinct values. This is important when deciding if a column should be an attribute or a member property.
The percentage of rows in each column that have non-empty and null values.
Relationships to other pipelines. When not provided by the data source, sample data loaded from the source will be used to try to detect relationships to other pipelines in the model.
Pipeline key. When not provided by the data source, the first column (reading top to bottom or left to right, depending on the data source) containing 100% granular (unique) data, according to the sample returned for profiling, is used as the default key.
Reporting properties (cube settings) from existing pipelines. Adding a warehouse pipeline (a new pipeline based on an existing one), or adding a lookup column will copy reporting properties (such as whether the pipeline is a dimension, or whether a column is an attribute or measure) from the original column or columns to the new column or columns.
Reporting properties (cube settings) from the profile. Default reporting properties are set according to the source metadata (if available) and the profile information.
Pipeline tabs
All pipelines have tabs containing information that can be configured.
SOURCE. Allows you to add source filters to load only selected rows from the data source, and to control incremental loading from the data source.
COLUMNS. Allows you to map columns, add lookups and calculations, add steps, and add filters.
RELATIONSHIPS. Allows you to add and configure relationships to other pipelines.
Each of these pipeline tabs appears below the pipeline's name. By default, the COLUMNS pipeline tab is selected.
Relationships
When a model is created, relationships are added between its pipelines. These relationships come either from the source database structure or metadata, where available (for sources such as SQL Server) or from the data profiling algorithm, which creates relationships based on field names and comparison of data from possibly-related fields.
Relationships are defined using the Relationships pipeline tab. You can view these relationships, edit and delete them, and create your own relationships, as needed. Pipeline relationships are used to create joins between the tables corresponding to the pipelines in the data warehouse.
Relationships allow you to add and configure relationships to other pipelines.
View relationships
Relationships may be viewed as outlined below.
Model screen relationships list. View a read-only display of relationships between pipelines.
Relationships tab. View and edit relationships for pipelines.
Select the pipeline whose relationships you want to view or edit.
Click the RELATIONSHIPS tab to display relationships between current and other pipelines in the model.
Pipeline Source settings
You can specify settings related to your pipeline's source (such as the data source being used) and its corresponding data table, using SOURCE pipeline tab. Settings can differ based on whether you are viewing a date or non-date pipeline.
Date pipeline source settings and the global date filter
Once the global date filter feature is enabled and the date range is defined for your model, you can use the settings in this area to determine whether the pipeline will be affected by the global date filter and which column gets filtered.
By selecting the Enabled check box, the other options become active:
Select the Detect date column automatically check box to configure the date column that is used to filter the pipeline based on relationships to the Date pipeline. If the Date column drop-down list is blank, no filter will be applied.
To manually select the date column, clear (uncheck) the Detect date column automatically check box and select the date column you want to use from the corresponding drop-down list.
When a date column is selected, the pipeline is filtered by the selected column, using the date range specified in the Date pipeline.
Calendar Configuration
Fiscal Calendar configuration
Regular Calendar configuration
Non-date pipeline source settings
When viewing non-date pipelines, the SOURCE pipeline tab displays three main areas: Data Source, Source Filter, and Global Date Filter. A Preview panel is available at the bottom of the tab.
 |
Several areas displayed in the SOURCE pipeline tab are outlined below.
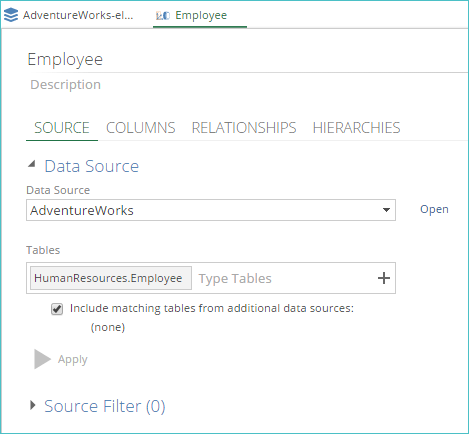
Data Source
This displays the pipeline's data source settings. These can be changed to override the inherited data source settings for the current pipeline.
The Data Source drop-down list displays the data source used by the pipeline. You can select a new data source for the pipeline, or you can open the currently selected data source by clicking the Open button. When clicked, the data source appears on a new tab.
The remaining options vary based on the type of data source that corresponds to the pipeline.
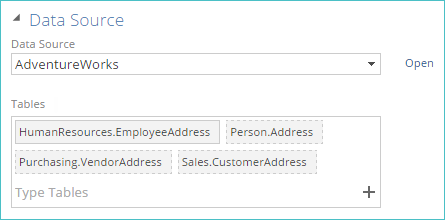
SQL Server / ERP / CRM
The tables tag control displays the tables in the currently selected data source used for the pipeline. You can add or remove tables using the tag control. Tables may also be added from multiple data sources.
Sheets
The Sheets tag control displays the sheets in the currently selected data source used for the pipeline. These sheets were initially specified when the data source was created. You can add or remove sheets using the tag control.
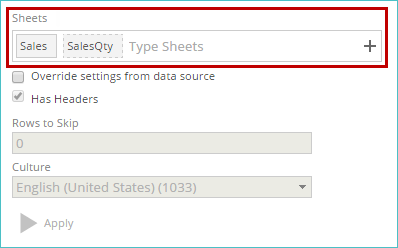
Data from all selected sheets are used when this pipeline is processed. Only sheets in the selected data source are displayed.
The sheet tag uses a solid border as the primary source sheet. Other sheet tags use a broken line border. A different primary source sheet can be specified by right-clicking a sheet and selecting Set Primary Sheet.
CSV
The Files tag control displays the files used for the pipeline. These files were initially specified when the data source was created. You can add or remove files using the tag control.
Data from all selected files are used when this pipeline is processed. Only files in the selected data source are displayed.
The file tag that uses a solid border is the primary file. Other file tags use a broken line border. A different primary file can be specified by right-clicking a file and selecting Set Primary File.
Note
Once a new data source or table is selected for a pipeline, you may need to make changes to the columns listed in the COLUMNS pipeline tab to ensure they still match your requirements.
Source Filter
This allows you to define row filters for the data that is copied from a table in the source database.

The source filter feature is configured in exactly the same way as the row filter feature. The difference is that row filters are applied to tables or views in the data warehouse, whereas source filters are applied to data as it is copied from the source database to the staging table in the data warehouse.
Note
Only some data sources support source filters. If the setting is not supported by the current data source, the Source Filter section displays Unsupported next to the setting itself.
A source filter will save time when network speed is a limiting factor.
Preview
View data directly from the source using the Preview area at the bottom of the SOURCEpipeline tab.
Editing the primary key
Selecting a column marked with a yellow key does not allow you to edit the columns of the pipeline’s primary key, but rather allows you to add or remove key columns to an attribute associated with the column. The column must be marked as an attribute for this feature to be available.
Override settings from the data source
For source table pipelines and source SQL pipelines, the default settings for the two incremental options (Default Incremental Type and Quick Incremental Type) are determined by the corresponding settings in the pipeline's data source. To adjust these settings for the current pipeline, select this checkbox and specify the options for the Default Incremental Type and Quick Incremental Type drop-down lists.
Note
The Override settings from the data source check box does not appear for warehouse, warehouse SQL, or Date pipelines, since they are not directly linked to the source and do not inherit settings from it.
Incremental Type
Default incremental type and quick incremental type drop-down lists specify the pipeline-level behavior for the two available types of incremental loading. The following options are available from each drop-down list:
Add and update is the default setting for the Default Incremental Type. When selected, new data from this pipeline is added and existing data is updated, as needed.
Add only is the default setting for the Quick Incremental Type. When selected, only new data from this pipeline is added. No existing data is updated.
Pipeline Settings
Pipeline panel
Pipelines have a pipeline design panel where pipeline behavior can be configured.
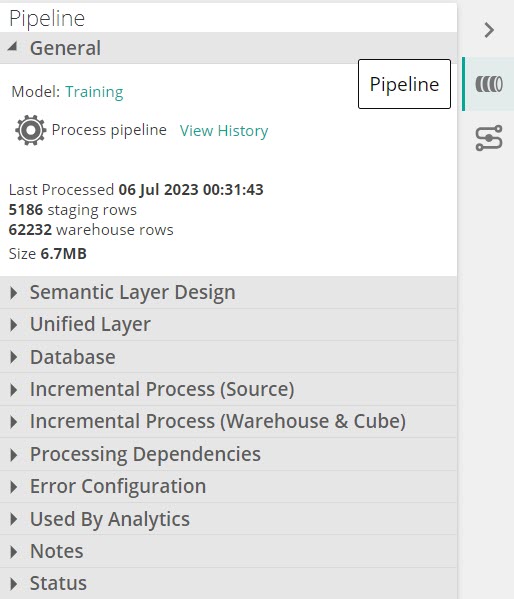 |
General
The following settings and information are available in the General area of the Design Panel.
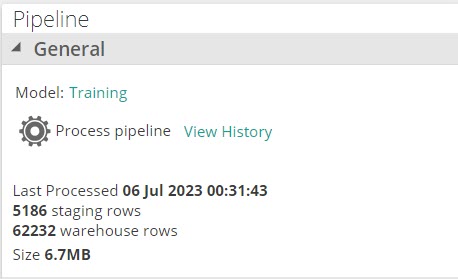 |
Model link. Opens the model that corresponds to the currently displayed pipeline. The model tab is shown, displaying all of the model's details including data sources, other pipelines, relationships, and process schedules.
Process Pipeline button: This allows you to process the current pipeline.
View History link: This allows you to see all current and previous processing information related to the current pipeline. The information is displayed on the Managed Background Tasks tab.
Last Processed: After a model or individual pipeline is processed, the date and time when the pipeline was last processed is displayed below the Process Pipeline button.
Staging rows: After a model or individual pipeline is processed, the number of staging rows for the pipeline are shown.
Warehouse rows: After a model or individual pipeline is processed, the number of warehouse rows for the pipeline are shown.
Size: After a model or individual pipeline is processed, the total size of the current pipeline is displayed.
Database
You can use a pipeline's properties to determine how the pipeline is stored and processed within the data warehouse.
These properties are available from the Database section of the Pipeline panel.
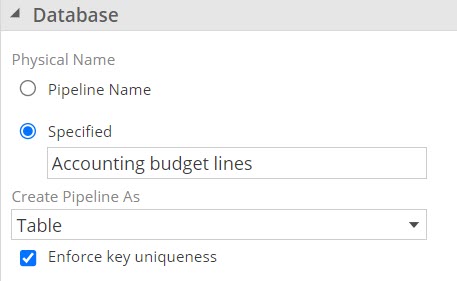
The following settings are available:
Physical name
This is the physical name of table in the SQL warehouse. By default, the table has the same name as the pipeline. If Specified isselected, the table's name may be entered manually in the adjacent text box. This feature may be used to retain compatibility with other applications that access the table, such as SQL Server Reporting Services.
You may want to specify an object's Physical Name property explicitly. You must ensure existing operations that refer to the database (such as SQL Server queries, or analytic tool reports) still work despite changing an object's display name.
Create pipeline as
This controls how the pipeline is manifested in the data warehouse. The following options are available:
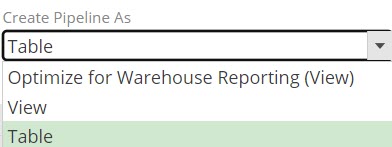
Optimize for Warehouse Reporting (View) - The pipeline will inherit this settings from the model. If the Optimize For Warehouse Reporting check box is selected (checked) at the model level, any pipeline that was previously using the Table setting will retain that setting, while any pipeline that was using the View setting will now inherit its setting from the model.
View - A view is a virtual table. It Decreases overall disk usage and processing time for the pipeline, but only if the pipeline is not referenced by other pipelines.
Table - Improves processing performance if other pipelines reference this pipeline.
History Table Name
If the pipeline contains a History step, this property displays the name of the warehouse history table. When a History step is used, the warehouse contains data that is temporal in nature and cannot be recovered from the source alone. For this reason, it is recommended that on-premise instances institute a backup process for this warehouse history table. This property shows the name of the table as it exists in the warehouse schema.
Clear History
If the pipeline contains a History step, you can use this option to delete the history table in the warehouse that corresponds to this pipeline.
Incremental process (Source)
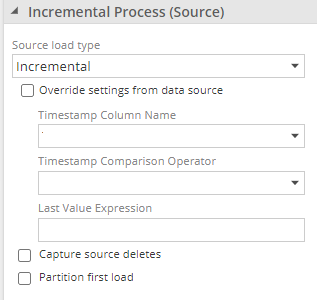
Source Load Type
Source load type specifies how data is loaded from the source.
Note
Source incremental configuration is only available for Source table pipelines and Source SQL pipelines
For source table and SQL source pipelines, changing these pipeline-level settings overrides the corresponding, inherited data source settings.
Incremental: When configured by selecting Override settings from data source, the settings specified here will be used for incremental load. When not configured in the pipeline, incremental settings specified on the data source will be used. More detail on Incremental
Full Refresh: Loads all the rows from this pipelines source. More detail on Full Refresh
Partitioned: Separates data into partitions based on a date column. Each partition is loaded as its own transaction. More detail on Partitioned processing
Load Once: This performs a full refresh on the first load and will be ignored in subsequent processes. More detail on Load Once
Incremental
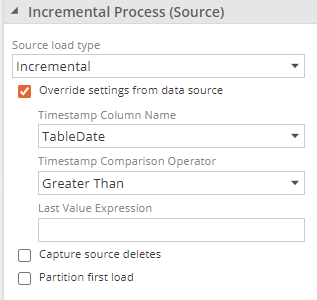
Selecting Override settings from data source enables the fields to configure incremental on the pipeline.
You can provide a timestamp column name that stores a timestamp (or other suitable value) in each table. After the first load, only rows with a timestamp greater than the date/time of the last load are appended to the staging table. Incremental loading saves time for most data sources and typically saves processing time for most data pipelines.
Overriding the timestamp options may be necessary if a particular pipeline uses a different timestamp column or comparison operator compared to its data source.
The following settings are available:
Override settings from the data source - The default options for these settings are determined by the corresponding settings in the pipeline's data source.
Timestamp Column Name - Specify the column name used as a timestamp for the pipeline.
Timestamp Comparison Operator - Specify which rows in each table of the data source are examined to determine if they are new. Two options are available:
Greater Than - This option loads only entries with a value greater than the highest value that was last loaded. In timestamp-based columns, using this option risks missing entries, as explained above. However, if the timestamp column is, say, a batch identifier, and there are many rows in each batch, it may be safe to assume that all the rows from each batch are written together and were imported on the last load. Furthermore, were Greater Than or Equal to be selected in this scenario, performance may be impacted if the batches contain many rows, as this would force all the entries from the last, previously-loaded, batch to be re-examined.
Greater Than or Equal to - This option is the safest, as it examines rows with a value in the timestamp column greater than or equal to the value of the highest value of the rows that were last loaded. Using this option guarantees that all new rows are found. For example, if a timestamp column has a resolution of say, 1 minute, it's possible that the last incremental load did not load all the rows written during that minute. Using Greater Than or Equal ensures that all entries for that minute are re-examined. Any entries already loaded are ignored.
Last Value Expression Use this option to change the selector for the incremental filter. The default is Max(@Column), which does not need to be changed
Partition First Load - In certain cases pipelines configured with incremental, can naturally be very large pipelines. The incremental process tends to be resilient, but when having to full load for the first time, or full subsequent full loads it can fail.
For enhanced resilience, this setting is available for just such cases which allows the first load or any other full refreshes from the source to be done with partitions. User's should NOT turn this on unless they are commonly finding their pipelines failing to load in theses situations.
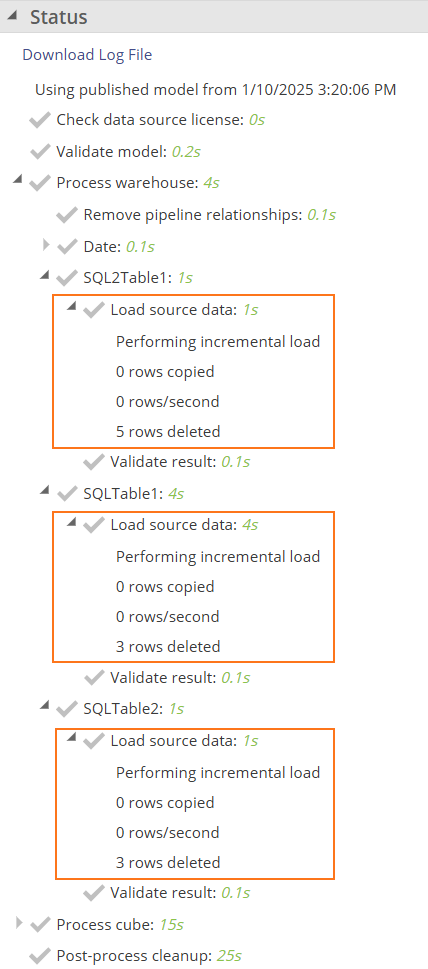
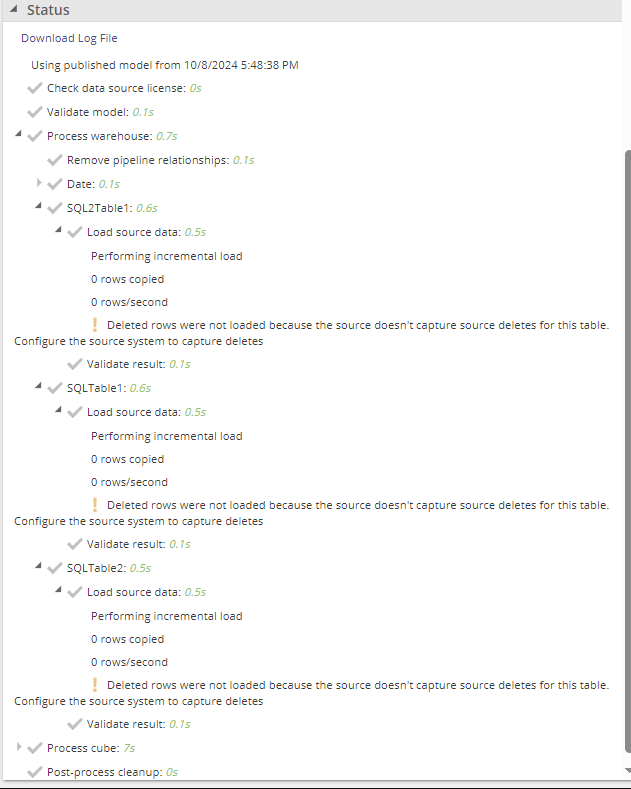
Capture source deletes - Enable to load and apply rows that have been deleted, in addition to added and updated rows. This is currently only available for data sources that support source deletes and require additional configuration. Configure Change data capture
When enabled, it will check during processing if the source has been configured to retain logs of deletes made. During source migration, it will remove any rows from the staging data that have been deleted from the source since the last process, while not affecting unchanged rows.
The processing tree will contain details per source table on how many rows have been deleted, or if the host system has not been configured to capture deletes
Full Refresh
A full refresh will load all data from the source and ignore any incremental settings.
Partitioned
The Partitioned Source load data type provides the ability to identify active source information, that is likely to be updated. All older data will be treated as historic and will not be reloaded again after its initial load.
Partition periods suitable to your data should be configured. For example, choosing a period of month, and 4 active partitions, and current date is 15 June, all data from 1 March to 15 June will be migrated over 4 partitions (Mar, Apr, May, Jun).
The range of active data will be split into smaller partitions and loaded individually, which makes loading large data sets more resilient. When loading partitions, functionality similar to incremental source load will be applied automatically. Through this functionality timestamps will be updated for only new and updated records, and deletes from the source will be synchronized. Also like incremental, incremental warehouse load will be supported."
Important
Partitioned source migration is only available for pipelines that is a source pipeline or a source SQL pipeline.
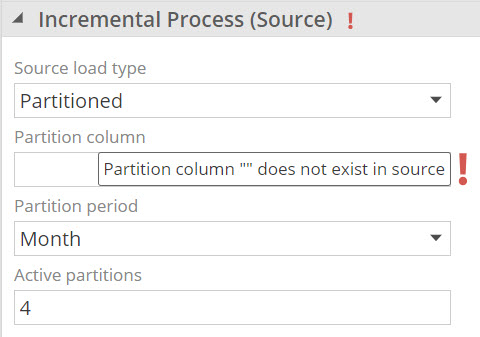
Partitioned processing settings:
Partition column Required needs to contain a date / timestamp column in the source. Data Hub will use this column to create partitions of data to migrate.
Partition period Required needs to be set appropriate to the individual nature of the source data. Possible values are Day, Month and Year
Active partitions Required can be any numeric number, which will indicate the number of periods(partitions) that is active data, to be loaded every time the pipeline is processed.
Load Once
Load Once will do a full refresh once only. This is useful when you have large amounts of historic data to bring in, but don't want to reload this on subsequent processes.
Incremental process (Warehouse)
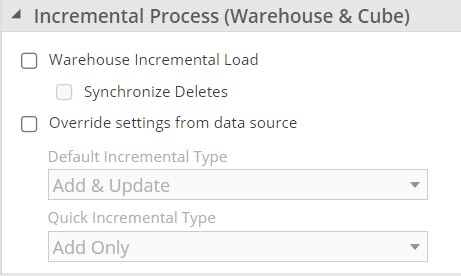
You can specify how data is loaded from the tables in the warehouse (with no direct source involvement) using the options in the Incremental Process (Warehouse & Cube) group on the pipeline's Design panel.
Important
These options are available for all pipeline types, including Date pipelines.
Warehouse Incremental Load - When selected, only rows not previously loaded from the source are loaded into the warehouse table, saving processing time. If the pipeline contains complex SQL steps or calculations that aggregate, disable this setting to ensure that the warehouse table is populated correctly.
Synchronize Deletes - With many database-type data sources, such as SQL Server, deleting rows from data tables is slow. To optimize performance, by default, when an incremental load is performed, only new rows are added and changed rows are updated.
Deleted rows are left in the table, and are removed when the next full update is performed. However, other data sources, such as Excel and CSV, may not have a similar performance cost for incremental deletes. If rows in the source table are deleted frequently, and the table is small, it may be worth selecting this check box.
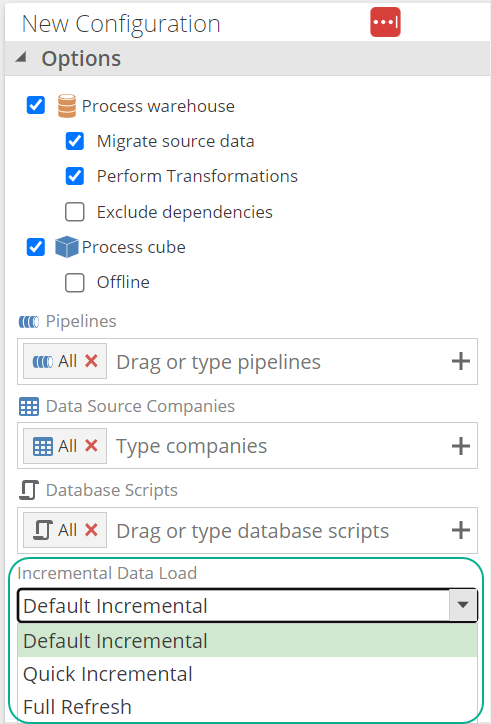
Note
Depending on the source database structure, the deleted rows may affect the accuracy of reports produced from the cube. To minimize this problem, you should perform a full load of the source data periodically to effectively remove the deleted rows. A full load can be achieved by creating a model process schedule with Incremental Data Load set to Full Refresh.
 |
In some data sources, such as Microsoft CRM, this problem is alleviated by not deleting rows, but rather flagging them as disabled. In this case, the need for periodic full loads to maintain report accuracy is eliminated.
Override settings from data source - For source table pipelines and source SQL pipelines, the default settings for the two incremental options (Default Incremental Type and Quick Incremental Type) are determined by the corresponding settings in the pipeline's data source. To adjust these settings for the current pipeline, select this check box and specify the options for the Default Incremental Type and Quick Incremental Type drop-down lists.
Note
The Override settings from data source check box does not appear for warehouse, warehouse SQL, or Date pipelines, since they are not directly linked to the source and do not inherit settings from it.
Default Incremental Type and Quick Incremental Type drop-down lists. Specify the pipeline-level behavior for the two available types of incremental loading.
The following options are available from each drop-down list:
Add & Update. The default setting for the Default Incremental Type. When selected, new data from this pipeline is added and existing data is updated, as needed.
Add Only. The default setting for the Quick Incremental Type. When selected, only new data from this pipeline is added. No existing data is updated.
Pipeline processing settings
Process specific pipelines within your model
You can process individual pipelines or groups of pipelines, instead of processing all pipelines (as when an entire model is processed).
You can select pipelines from the Pipelines list on a model's tab, or you can specify the pipelines directly on the Process screen.
When processing pipelines, only affected measure groups and dimensions are processed, as opposed to the entire cube. This behavior increases the overall speed of pipeline processing.
Selection methods:
Select Pipelines from the Pipelines List.
Specify individual pipelines directly on the Process Screen.
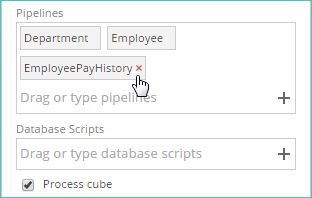
Remove pipelines from a process:
If you have added a pipeline to the Process screen (or to the Properties Design Panel), but you decide that you don't want to process it, you can remove it using the small "x" button that appears when you hover over the pipeline's entry in the corresponding text box.
 |
Dependencies
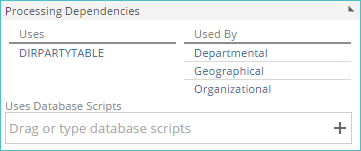
You can view processing dependencies for the current pipeline by examining the new Processing Dependencies area of the pipeline Properties Design Panel. A pipeline depends on another pipeline if there's a lookup, warehouse pipeline, calculation, or SQL step in the pipeline that references the other pipeline.
 |
The following information is displayed:
Uses column - A list of other model components that the current pipeline relies on when it is processed.
Used By column - A list of model components that rely on the current pipeline when they are processed.
All listed model components (in both columns) are links (in both columns) which, when clicked, open the corresponding item in a separate tab.
Uses Database Scripts - This specifies the database scripts that must be executed before the current pipeline can be processed. The actual moment of script execution in the overall process depends on the individual script's Typesetting.
Error configuration
You can use the Error Configuration pipeline property to control what happens if an error occurs while processing the pipeline.
The following options are available:
Continue. An error will cause this pipeline to be marked as an error in the log file. However, other pipelines and downstream objects will continue to be processed. This option guarantees that a result is produced even if the pipeline has an error, but risks providing incorrect data that you are unaware of unless you check the processing log.
Fail. This is the default option. An error will cause the entire process operation to stop and be marked as an error. No additional pipelines, nor downstream objects, will be processed.
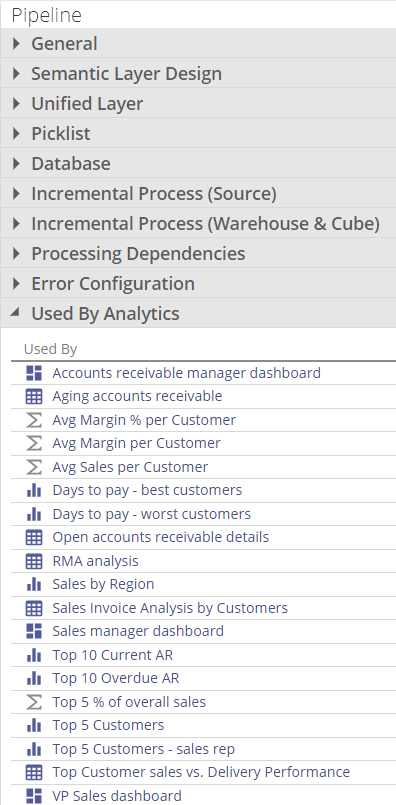
Used by Analytics
All Analytics that are using a particular pipeline is shown in this list
View pipeline status
During model processing, you can view the status of the task using the Status area.
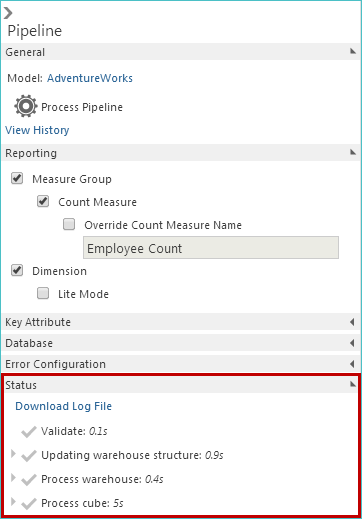 |
View individual pipeline information
Pipeline List - Click a pipeline in the pipeline list to view the pipeline's information in a separate tab.
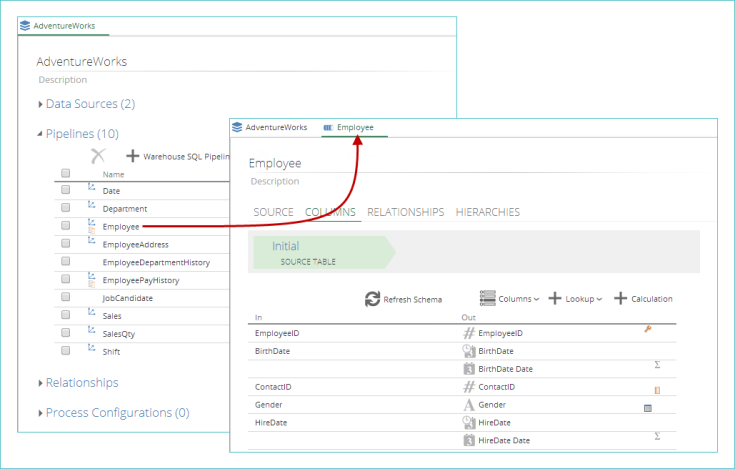 |
The pipeline's tab displays the following information (which can be edited):
The pipeline's name.
The pipeline's description.
The pipeline tabs (SOURCE, COLUMNS , etc.
The pipeline's properties.
Info tip - Hover over an individual pipeline to view its info tip.
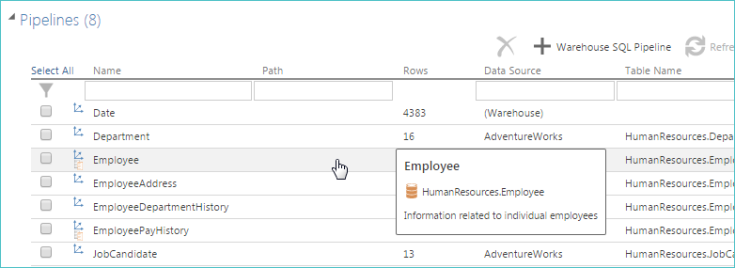 |
This info tip displays additional information such as:
The pipeline's display name
The pipeline's database name (noted by the database icon)
The pipeline's description (if one has been defined)
Refresh pipeline schema
You can use the Refresh Schema button to verify that you are viewing the most up-to-date column schema from the data source for the selected pipeline.
Once you select one or more pipelines, the button becomes available (It is no longer dimmed).
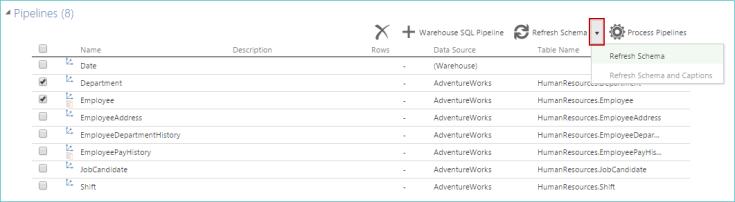 |
The button has two options, displayed in a drop-down list:
Refresh Schema. Refreshes the column schema, column display names, and column descriptions from the data source for the selected pipelines. Also refreshes the column schema for each step, which includes refreshing the data type for lookup columns and applying any SQL steps.
Refresh Schema and Captions. Performs the same actions as the Refresh Schema option above as well as the following additional operations:
Updates pipeline display names and descriptions.
Updates column display names and descriptions, even if they were previously edited in the initial step.
Note
The refresh process may take longer for data sources without column schema information, as the data must be profiled to produce the schema. Any user-defined customizations for the above properties may be overwritten.
The Refresh Schema and Captions option is only enabled for some data sources.
Pipeline key columns
Each pipeline must have a unique primary key defined for its initial step, and usually has a primary key defined throughout. A primary key consists of one or more columns. These are marked with a small key symbol at the right end of the column's entry in the pipeline schema.
There are two kinds of key columns: main key and additional key. The types are distinguished by the color of the key icon. A blue key icon indicates the main key column and a yellow key icon indicates an additional key column.
If only one column is specified as the primary key, it will be marked as the main key column.
If more than one key is included (composite key), the main key will appear with a blue icon, and the additional keys will appear with yellow key icons.
The main key column is significant in three ways:
It will appear as the first column in the pipeline schema, with any additional key columns indented immediately below.
If the pipeline is a dimension, the primary key attribute will be named for the main key column.
Editing the pipeline's primary key is done by first selecting the main key column.
Note
Any changes made to the keys will not take on their ultimate positions until the pipeline is closed and reopened to refresh the schema.
In a composite key, the choice of the main key column has no effect on the key behavior, other than the points listed above. It is usual, but not required, to choose the most granular column as the main key.
Examining the key columns shown for the initial step indicates the keys that are used for the staging table (the one that is imported directly into the warehouse from the data source). There must be a unique key at this step as this is required for incremental loading to work correctly. An error will display when the pipeline is processed if the key is not unique.
If there is more than one step in the pipeline, the key columns for the initial step and the non-initial steps may be different. You may change the keys (e.g. to alter the granularity of a dimension) or remove them entirely (e.g. when a measure group pipeline has no suitable key columns) on any step after the initial step.
Changes made to the primary key in the initial step will automatically be made in all non-initial steps if the steps have the same setting as the initial step (if no key customization has been performed on the non-initial steps).
Examining the key columns shown for any non-initial step in the pipeline indicates the keys that are used for the warehouse tab (the table that is created as the result of the pipeline). If the pipeline is marked as a dimension in the cube, these keys will also be used as the primary key attribute in the dimension.
All non-initial steps in the pipeline will display the same key. Changing the key columns for any non-initial step will automatically update them for all other non-initial steps.
Indexes
Indexes are data structures that improve retrieval speed. They are used to quickly find data without having to search every row in a database table every time the table is accessed.
Managing pipeline indexes
An existing pipeline index may be modified by:
Adding a column.
Changing a column.
Removing a column.
Additionally, an entire index may be permanently deleted from the pipeline.
Pipeline properties
Override settings from data source - For source table pipelines and source SQL pipelines, the default settings for the two incremental options (Default Incremental Type and Quick Incremental Type) are determined by the corresponding settings in the pipeline's data source. To adjust these settings for the current pipeline, select this check box and specify the options for the Default Incremental Type and Quick Incremental Type drop-down lists (described below).
Note
The Override settings from data source check box does not appear for warehouse, warehouse SQL, or Date pipelines, since they are not directly linked to the source and do not inherit settings from it.
Default Incremental Type and Quick Incremental Type drop-down lists. Specify the pipeline-level behavior for the two available types of incremental loading.
The following options are available from each drop-down list:
Add & Update. The default setting for the Default Incremental Type. When selected, new data from this pipeline is added and existing data is updated, as needed.
Add Only. The default setting for the Quick Incremental Type. When selected, only new data from this pipeline is added. No existing data is updated.
Appendix
Configure CDC (Change data capture) for SQL Server
Currently only the following data sources in Data Hub support Capture source deletes.
SYSPRO
SageX3 (only MsSqlServer)
MsSqlServer
In order for Data Hub to process incremental source deletes on a SQL Server source, CDC has to be enabled. Detailed information about Change data capture
Ensure the SQL server agent is running.
Enable Change data capture on the SQL server database, using the following command:
`USE MyDB
GO
EXEC sys.sp_cdc_enable_db
GO`
Enable CDC on every table that requires source deletes.
`USE MyDB
GO
EXEC sys.sp_cdc_enable_table
@source_schema = N'dbo',
@source_name = N'MyTable',
@role_name = N'MyRole',
@filegroup_name = N'MyDB_CT',
@supports_net_changes = 1
GO`
Useful Links
How to bring data into your model with pipelines
How to Relate your Pipelines Modeling