Cloud release notes September 2022
Release number: K61
Modeling enhancements
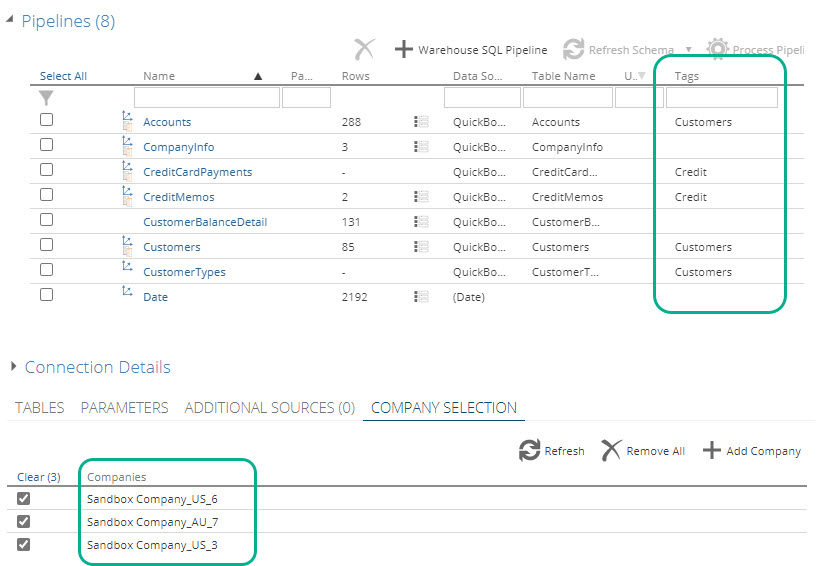
Processing per Company or per Tag
Per company and per tagged pipelines processing are new additions to model processing. It gives users the ability to process their models only for a specified company or group of tagged pipelines within the Data model, and not necessarily processing the entire model.
Pipeline tagging is achieved by adding labels in the tags column on the model screen pipeline grid, to logically group pipelines together. More information about Modules and tags
This feature becomes very useful to organizations that have several companies and/or large data sets. The enhancement can impact performance positively by reducing the amount of data to refresh, and therefore reduce processing time and removing data that is not required at any given point in time. Detailed information can be found in Processing parts of a model.
Process per company and process per tag have also been incorporated in a new version of the Model Process API
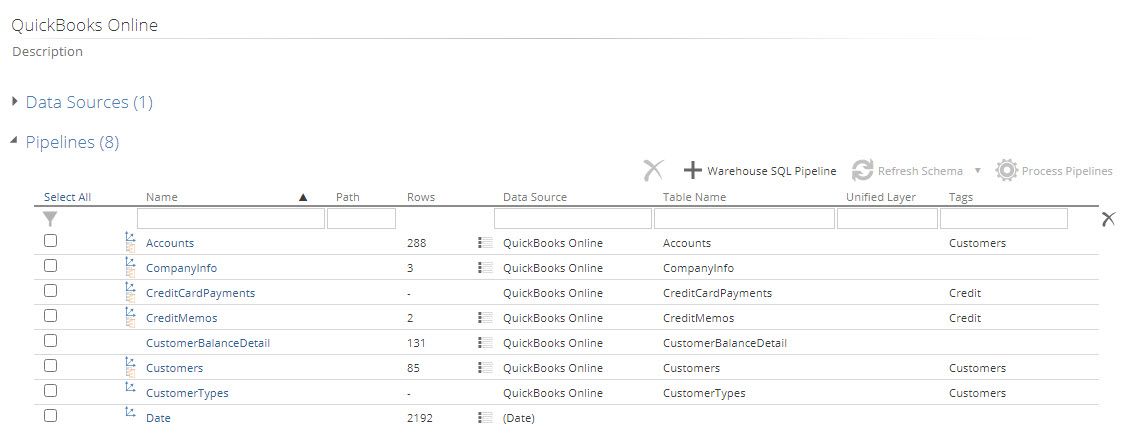
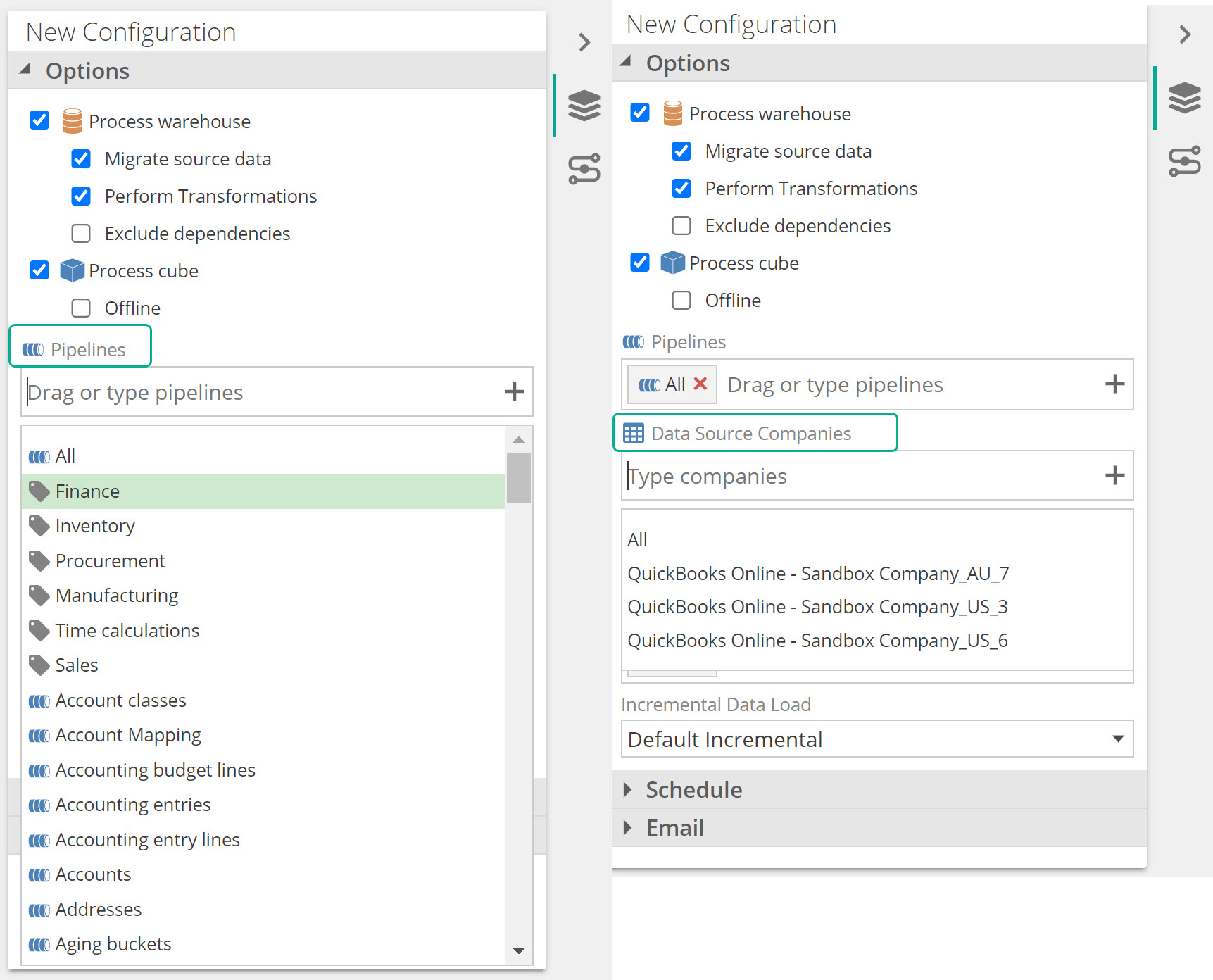
Both these new settings are available in two areas:
- A new Data Source Companies input text box, and new Tag items in the Pipelines dropdown, on the model process pop screen..
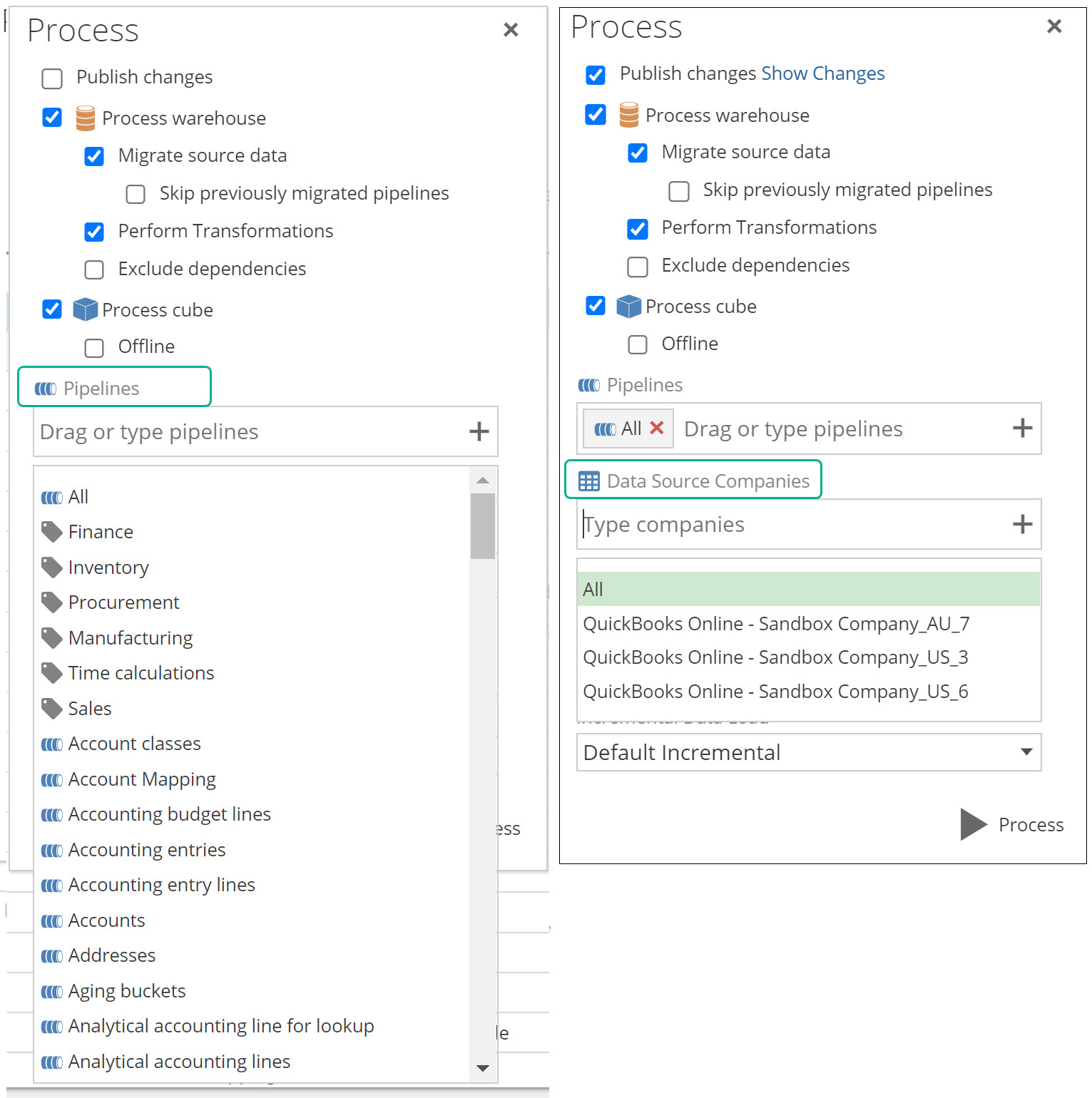
The process configuration setup panel.
Note
The Data Source Companies dropdown will be greyed out, if the data model does not use at least one datasource that supports a COMPANY SELECTION tab.
Model Processing resilience on Azure SQL
Additional resilience have been built into model processing. If any Azure SQL configuration changes take place, automatic retry logic will ensure that the model processing continues, by re-trying on the failed partition of failed pipelines, instead of failing the entire model process.
Partitioned pipeline processing
Processing selected amounts of source data has become increasingly important for customers with large data sets. Another exciting enhancement has been added to assist in configuring subsets of source data to migrate.
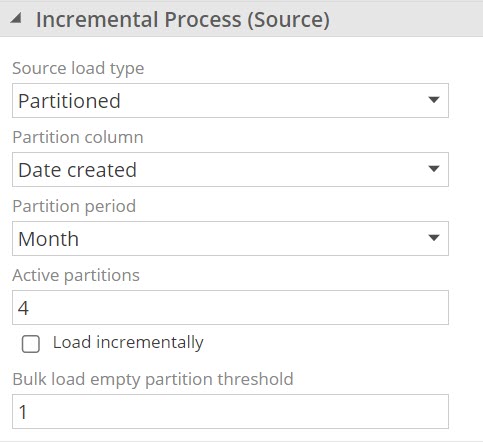
Partitioned pipeline processing provides the ability to migrate only periods of active source information based on date partitions, using a suitable date column, instead or reloading a full data set. For example, a large transaction table can be set to a Partition period of Month, and Active partitions of 4 which will process all data for the four months leading up to the current date, including the month of the current date. If current date is 15 June, all data from 1 March to 15 June will be migrated.
Configuration for this feature can be set in the Incremental Process (Source) section of individual pipelines. Detailed information about Partitioned processing and configuration
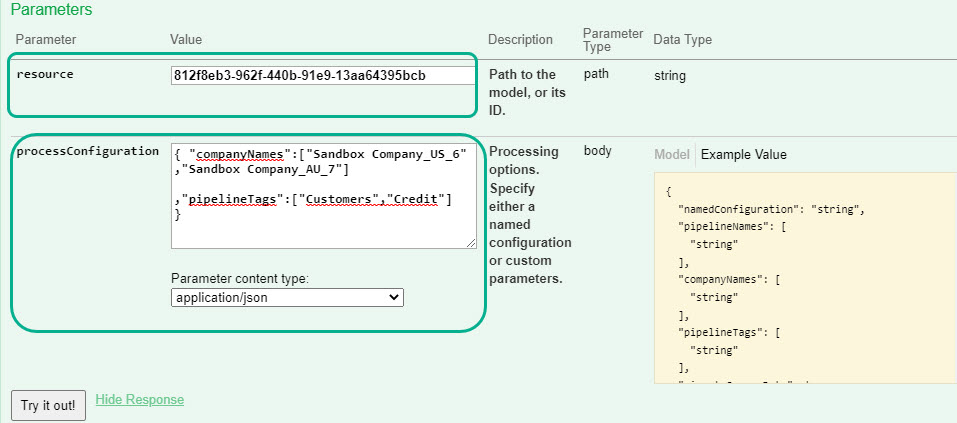
Model Process API
A new version of the Data Model Process API has been released. Its main functionality is still to process a model, but has been enhanced to accept additional parameters to further fine tune the HTTP requests.
Two parameters in particular to take note of:
Process a subset of companies.
Process a subset of pipelines by using tags
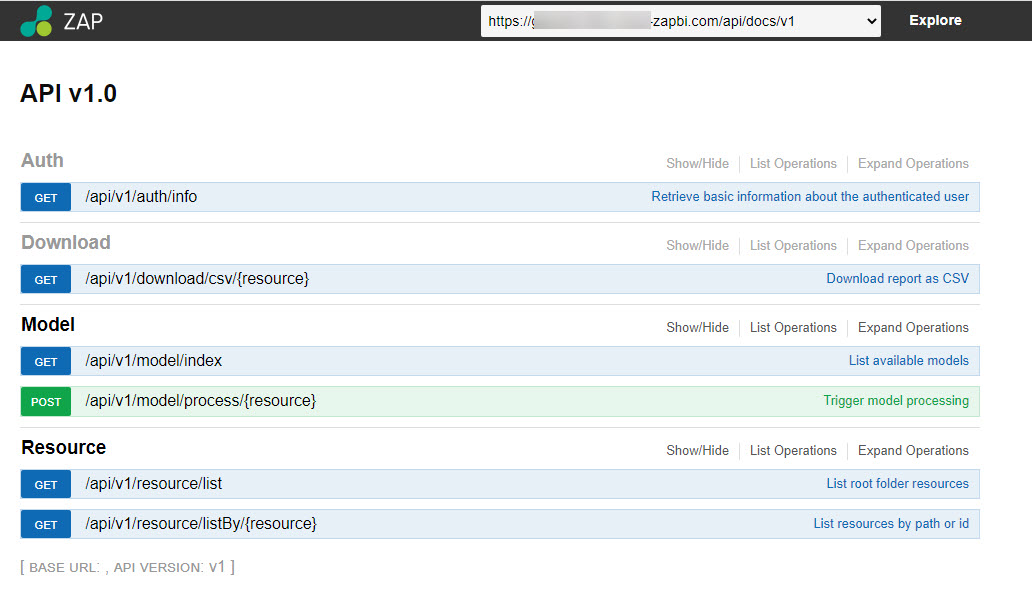
A new interface has also been made available to facilitate building, easy testing and provide detailed, technical documentation about the API. Read more about How to use the API
Note
The legacy Model Process API is still available. Legacy Model Process API
Performance Enhancements
Every release contains performance enhancements and bug fixes to improve Data Hub.
Date of publication 31 August 2022