CSV
CSV files are a type of flat file. You can connect to a single file, folder or .ZIP file that contains your data source information. The .CSV file can also be uploaded into the model.
Add a CSV file
A CSV file can be added to a new or existing model.
Select source
Under Files & Other select CSV.
From the source type pop-up, click Connect.
Connect
Complete the following fields:
File Location. Specify the location of the .CSV file using one of the following methods:
Windows File Share. Type the path of a folder, a .CSV file, or a .ZIP file in a network location that is accessible from the ZAP Data Hub web server (for example \\Server\SalesFolder\Sales.csv). If the location is a folder or a .ZIP file, all the available .CSV files within it are loaded, depending on the Files Filter setting. The referenced file or folder is reloaded each time the warehouse is processed.
HTTP/HTTPS. Type a URL for downloading a .CSV file or .ZIP file using the HTTP protocol (for example http://csvfiles/Sales.csv). If the URL refers to a .ZIP file, all the available .CSV files within it are loaded, depending on the Files Filter setting. The referenced file is reloaded each time the warehouse is processed.
Upload. Click the Upload File button to locate a .CSV file or a .ZIP file on your local computer. The file name appears in the box. If the location is a .ZIP file, all the available .CSV files within it are loaded, depending on the Files Filter setting. A static copy of each .CSV file is uploaded into the data model. The files are not reloaded automatically when the warehouse is processed.
Note
Uploading a CSV file has a storage limit. The default limit is 1000MB but can be changed in the settings by an administrator.

User Name. Specify a user name to connect to the specified file (if needed). If left blank, the ZAP Data Hub application pool service user's credentials are used. The following authentication types are available:
Windows File Share.
Active Directory User.
Basic HTTP Authentication.
Password. Type a password for the user name specified above, if needed.
Files Filter. If you are specifying a folder or .ZIP file using the File Location text box above (rather than a single file), this setting allows you to determine the types of files read by the data source. By default, only .CSV files are read.
Single Table. If more than one .CSV file is found in the folder or .ZIP file specified using the File Location text box, you can combine them into a single table using this setting. Otherwise, a table is created for each individual .CSV file in the folder or .ZIP file.
Has Headers. When selected, the first row of the .CSV file is assumed to contain the column names and is not included as a data row in the pipeline.
Rows to Skip. Specify the number of initial rows to ignore. This option should be used if the data in the file does not start at the first row. The number of rows specified in this setting is skipped first to reach the start of the data, then, if the Has Headers setting is selected, the next row is skipped before starting to import the data.
Culture. The culture determines how numbers and dates in the file are parsed as they are imported.
The culture includes settings for the decimal point character and for the order and format of day, month and year values within dates (for example, dd/mm/yy or mm/dd/yy).
For more information on available cultures and their settings, refer to the following website:
http://msdn.microsoft.com/en-au/goglobal/bb896001.
Delimiter. Specify the character used to separate the fields within each line of the file. The default setting is a comma (,). You can select commonly used delimiters from the corresponding drop-down list or specify the delimiter manually by typing it directly into the text box.
Quote. Fields containing a newline character sequence, or the delimiter or comment characters must start and end with the quote character. The default setting is double quotes (").
Escape. To include the quote character within a field that's already enclosed by the quote characters, precede it with the escape character. The default setting is double quotes (").
Comment. If a line begins with the comment character, all subsequent characters on the line are not imported. The default setting is the number sign or hash (#).
Select Data
To add tables from the data source to the Data Model:
Select tables to be added as pipelines using the check box column.
To add the pipelines to the data model, there are two options:
Use Add Pipelines to add tables as individual pipelines.
Use the Add Pipeline as Union of Tables option from the Add Pipelines drop-down menu, to add a single pipeline created from a union of the selected tables.
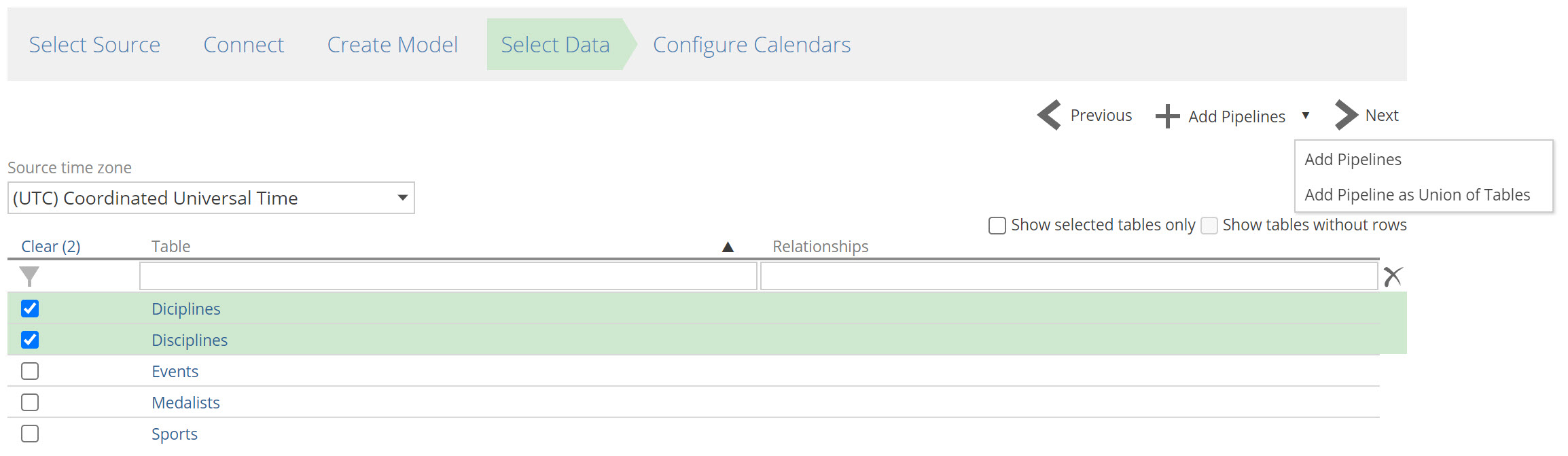
Click Next.
Detailed CSV parsing specification
When a .CSV file is used as a data source, it is parsed into records (rows) and fields (columns), which then appear in a pipeline in the model. For the parser to work, the file must have a valid structure. The required structure of a CSV file, and the operation of the delimiter, quote, escape and comment characters are outlined below.
Note
In the examples provided below, square brackets are used as delimiters for the example text, so they are not confused with the various delimiter and quote characters used in the examples. Parsed results are also shown delimited with square brackets. For clarity, the space character is shown as a small triangle (∆).
The file must consist of Unicode characters only.
The file is made up of records. There is one record per line, terminated with a newline (line break) sequence. A new line may be either of the Carriage Return (Unicode U+000D) or Line Feed (Unicode U+000A) characters, or both characters, in any order.
You may specify whether the file has a header line or not.
You may specify which culture (LCID) is to be used when parsing dates and numbers.
You may define four special characters:
The delimiter character. This defaults to the comma (,).
The quote character. This defaults to the double quote (").
The escape character. This also defaults to the double quote (").
The comment character. This defaults to the pound or hash sign (#).
Each record has one or more fields, terminated by the delimiter character.
Each record must have the same number and sequence of fields.
Each field may be quoted by enclosing it within the quote character. For a field to be validly quoted:
The quote character must be the first character in the field, including white space characters. It must immediately follow the field’s initial delimiter character, or be at the start of the line if the field is the first one in the line.
A second quote character must appear in the field (or an error occurs).
Note
Whitespace characters (space, tab, newline) following the second quote character in a field, but before the field’s final delimiter, are ignored. For example, the text [,"Smith"∆,] will result in a field containing [Smith] only. Non-whitespace characters after the second quote character in a field will cause an error. For example, the text [,"Smith"∆John∆,] will cause an error. Additional quote characters preceded by the escape character within a quoted field are ignored for the purposes of determining the second quote character. For example, the text [,"John∆(""Johnny"")"∆,] contains six double quote characters, but those surrounding Johnny are effectively quote characters preceded by the escape character. The final quote character is regarded as the second quote character. This text would parse to [John∆("Johnny")].
Fields containing any of the following characters shown below must be quoted (as described above), if they are to be interpreted correctly:
A newline character sequence.
The delimiter character anywhere in the field.
The comment character as the first character in the first field of a record (making it the first character on the line, which would otherwise make the entire line a comment). Quoted fields containing newline sequences have those newline characters included in the field. For example, the text [,"Smith,∆John",] will parse as a single field [Smith,∆John].
A quote character within a quoted field must be represented by the escape character followed by the quote character. If the default double quote character is used for both the escape and quote characters (as shown above), this means that a double quote character within a quoted field must be represented by two successive double quote characters. For example, the text [,"Jonathan∆(""Jonny"")",] would parse to [Jonathan∆("Jonny")].
If a field is not quoted (meaning the first character after the delimiter is not a quote character), any quote characters within it are interpreted normally as part of the field, and do not need to be preceded by the escape character. For example, [John∆("Johnny")] would parse unaltered to [John∆("Johnny")].
Lines marked as comments are ignored by the import process. The comment character must be the first character on the line (including white space characters). The entire line is then ignored. For example, the line [#The lines below are the new customers] will be ignored.
Leading white space characters (space or tab) at the beginning of a field (in other words, spaces or tabs immediately following a delimiter character) are included in the field. The leading spaces cause the quoting function of any subsequent quote characters to be ignored. The field will be treated as an unquoted field. For example, the text [,∆"Smith,∆John",] will parse as two fields, rather than one because the first character is not a quote. The first field will parse as [∆"Smith], and the second field will parse as [∆John"].
Trailing white space characters (space or tab) at the end of an unquoted field (spaces or tabs immediately preceding a delimiter character) are included in the field. For example, the text [,Smith∆,] will parse as [Smith∆ ].
Trailing white space characters (space or tab) at the end of a quoted field (in other words, spaces or tabs immediately following the last quote character, which immediately precede a delimiter character) are ignored. For example, the text [,"Smith,∆John"∆,] will parse as a single field [Smith,∆John].