Columns
Overview
The COLUMN tab provides column-related information in the following table format display:
In column - Represents the column’s name as it appears in the data source (for the Initial step) or in the previous step (for all subsequent steps). Some data sources allow the application to show easy-to-read names in this column.
For the Initial step, these source column names display both the caption and physical name (in parenthesis) if a caption is present in the source data (e.g., Dynamics CRM data sources). This formatting matches the format displayed when the Columns button is clicked.
Out column - Represents the column’s name as it will appear in the next step or, if it’s in the last step, how it will appear when it is used in reporting. It also includes icons showing the data type of the column.
Icons column - Displays icons showing properties for the column (such as measure, attribute, calculated column, etc.)
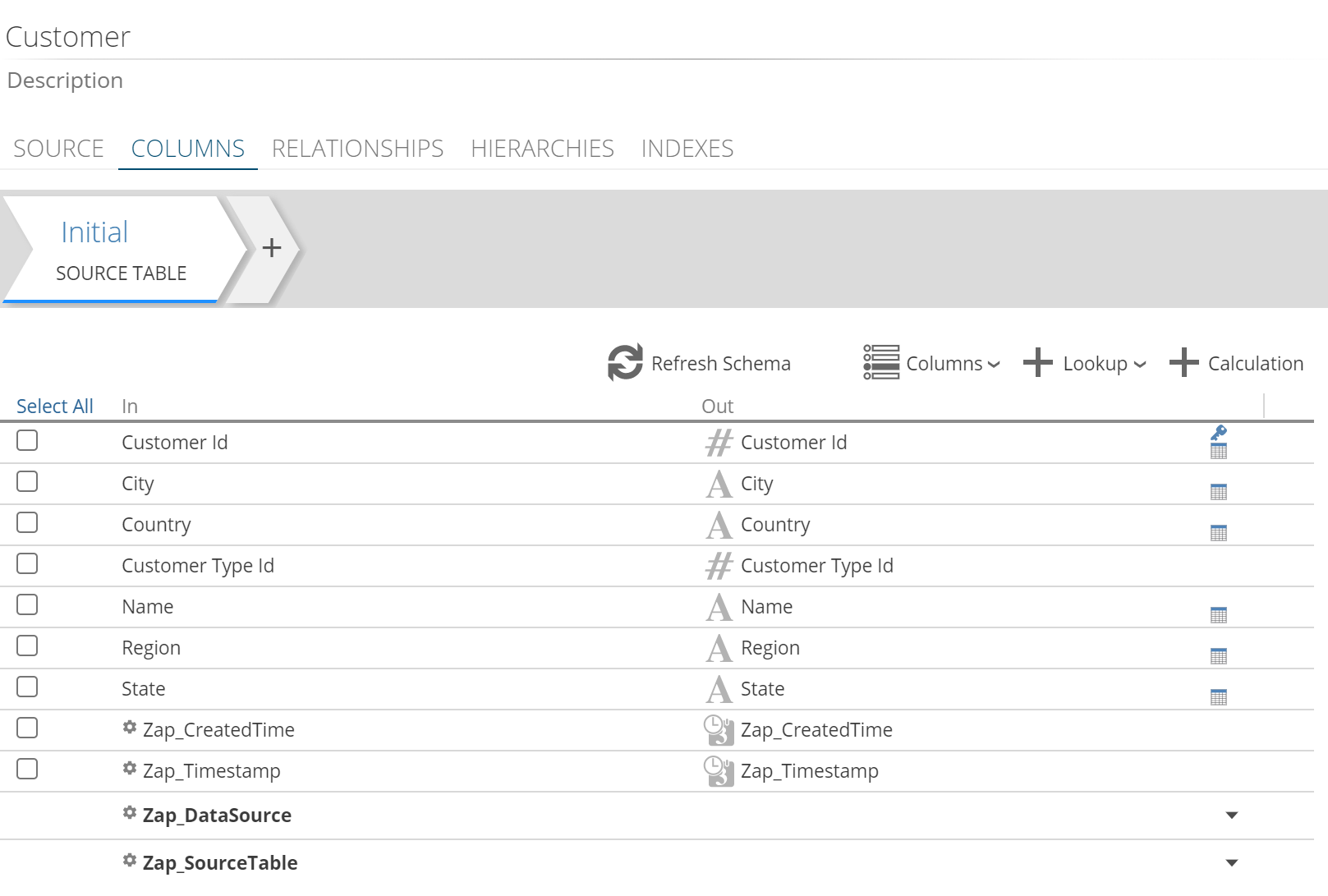 |
Column data types
Change a column data type
Note
If a column's data type is changed, and that column is used as a lookup, the corresponding lookup column's data type is also updated so that both columns' data types are the same.
Selecting data types
Binary and Text types - Whenever possible, length values are extracted from the source data (such as when using a CRM data source). However, this length data is not supplied with all data source types.
Text columns - A default value of 450 is used for all non-reported length values (when the length is not defined in the source data, such as with CSV or Excel data sources). If you know that your column length needs to be greater than this default value, you'll need to change it to avoid having the data truncated manually.
Note
The icon for the new data type appears on the Data type button itself and in the step's Out column. If the selected data type differs from the data type extracted from the source, the original data type's icon appears in the In column.
Column profiling
Profiling Settings
The Profiling Settings area contains properties that allow you to refine the profiles created for each column.
The following setting is available in this area:
Rows to Profile - This value determines the number of rows in each table of the data source that are examined to build up a profile of each column. The column profiles are displayed as tooltips when hovering over the column in the pipeline schema. Column profiles are also used to set column widths and build relationships for data sources that do not have relationship metadata. The value is a tradeoff between accuracy and speed and varies between data sources. Internet-based data sources may be too slow to allow profiling large numbers of rows. Increase the value if the profiling information seems inaccurate. Decrease it if profiling is taking too long.
Detect Relationships from Data. Specify whether or not any existing relationship information will be detected and included for all pipelines in the data source. Skipping this detection step (clearing the corresponding check box) can speed up adding pipelines, and the relationships can be defined later.
Column settings
Column database properties
This physical name is the name of the object representing a model, pipeline, or column used in the model's database. In contrast, the Name property of a model, pipeline, or column is the name displayed to users of the model.
You may want to explicitly specify an object's physical name when you need to ensure existing operations that refer to the database (such as SQL Server queries or analytic tool reports) still work despite changing an object's display name.
Note
Columns of type date/time are truncated to remove the time component. These "truncated date" columns have _DV added as a suffix (to the end of the physical name).
Used by Analytics
All analytics using a particular column is shown in this list
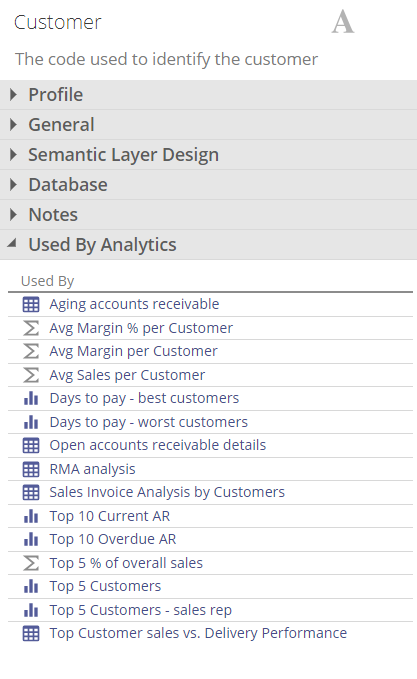 |
Lookup columns
Lookups let you use a foreign key field in one pipeline to add a more readable value from a related table.
For example, in a Customer pipeline, you could use the Customer Type ID column to get further details. This lookup process is also known as denormalization, as it results in columns containing repeating non-key values. Although this results in a larger table, it makes the cube structure simpler and easier to use.
New lookups are created using the COLUMNS pipeline tab.
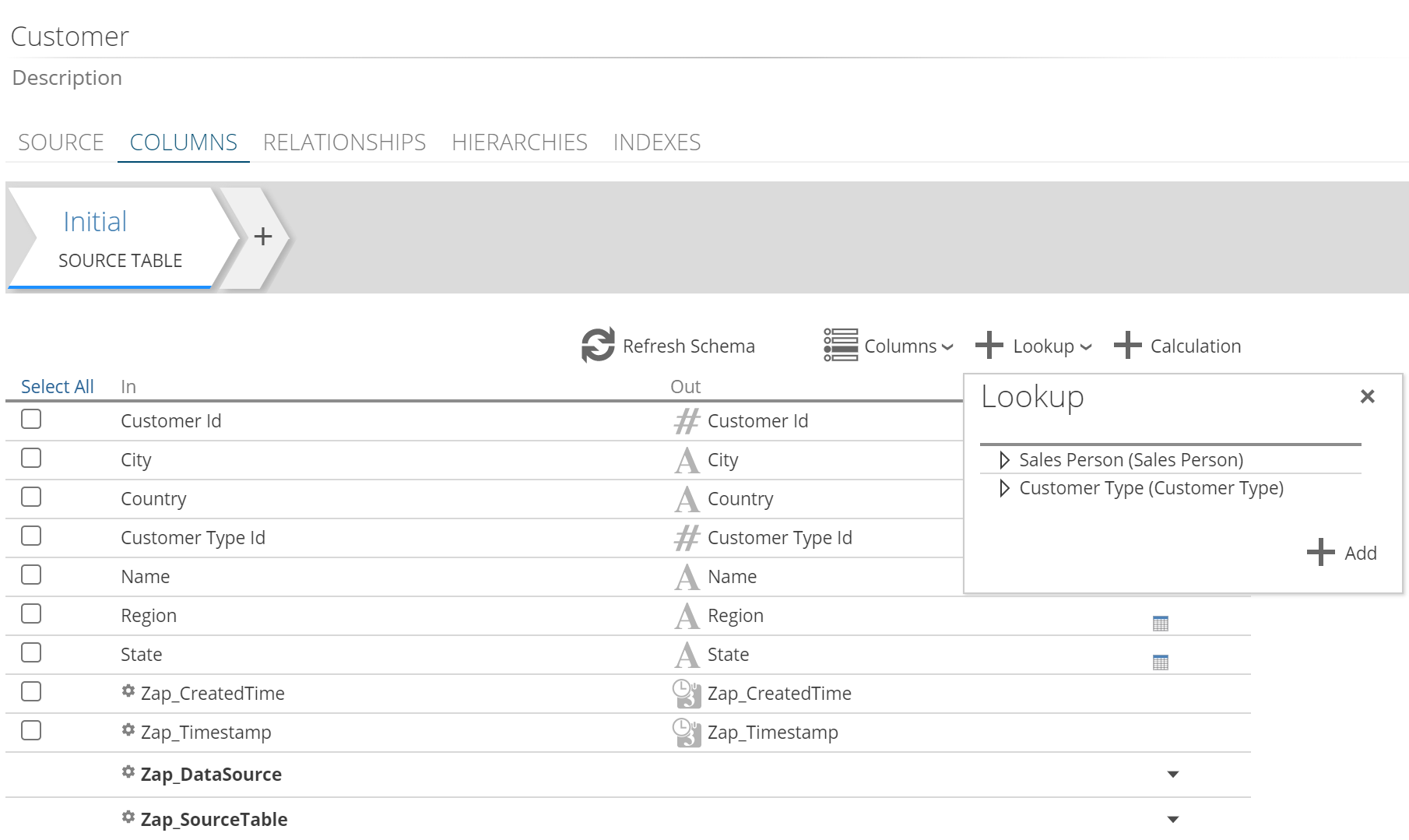 |
Lookups are always performed before calculations in each step. You can define a lookup and a calculation in the same step, allowing you to define a calculation on a lookup column.
To perform a lookup on a calculated column, you must configure the calculation in one step and then add a lookup on the calculated column in a subsequent step. Once added, the lookup appears in the columns list. A small magnifying glass icon at the right of the entry indicates that it is a lookup column.
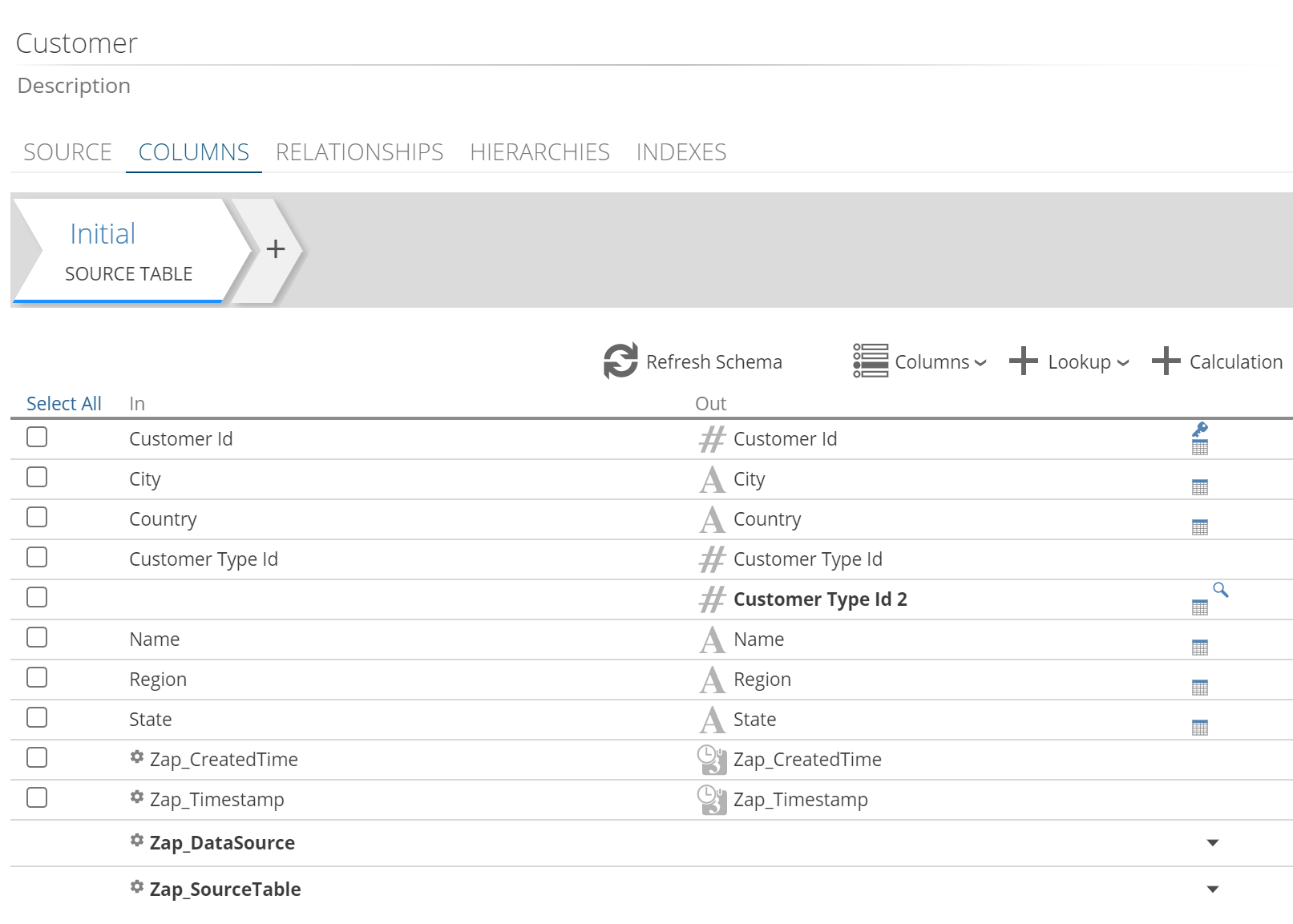 |
Note
To create a lookup, a relationship must already exist between the current pipeline and the pipeline that contains lookup information.
You do not need to retain the foreign key column in the step's output, although you may keep it if needed.
Setting column lookup properties
When using a lookup, an additional group of settings are available in the LOOKUP tab on the Properties pane and can be accessed by clicking the tab's title.
The Relationship entry portion of the path summary is also a link. Clicking it opens the corresponding RELATIONSHIPS pipeline tab and highlights the specific relationship the lookup is using.
Calculated columns
You can add calculated columns to a pipeline. A calculated column uses any valid SQL expression to calculate a column value from one or more other columns.
Calculated Column function templates are user-friendly function templates for creating Calculated Columns in pipelines. They provide predefined SQL-based functions, allowing users to create basic Calculated Columns on pipelines without knowledge of SQL expressions.
Tip
Example
Calculate the sales tax payable on each sale by multiplying the Amount column by 10%. The T-SQL expression would be: [Amount] * 0.1Note
Single-column keys
Add additional key columns to an attribute column
Increase the granularity of an attribute (other than the main key column of the pipeline's primary key) by adding additional columns to the attribute's key.
Important
This feature cannot be used if the main key column of the pipeline's primary key is selected. Adding keys to the main key column creates a composite primary key for the pipeline.
To make an attribute with a composite key useful, you will usually need to add a name column that unambiguously identifies each member. Do this by creating a calculated column that concentrates the values from each attribute’s key columns and then sets the calculated column as the attribute’s Name column.