Data Hub 10.1 on-premise release notes
Released May 2022
This release includes several new features, enhancements and defect resolutions.
Analytics enhancements
Public links
Improvements on the existing Get Link feature have been made, and includes simplifications of the UI which include better descriptions, enhancements to the user experience to make it easier to understand links, and view and copy them directly from the dialog. A new Public Links feature has also been added.
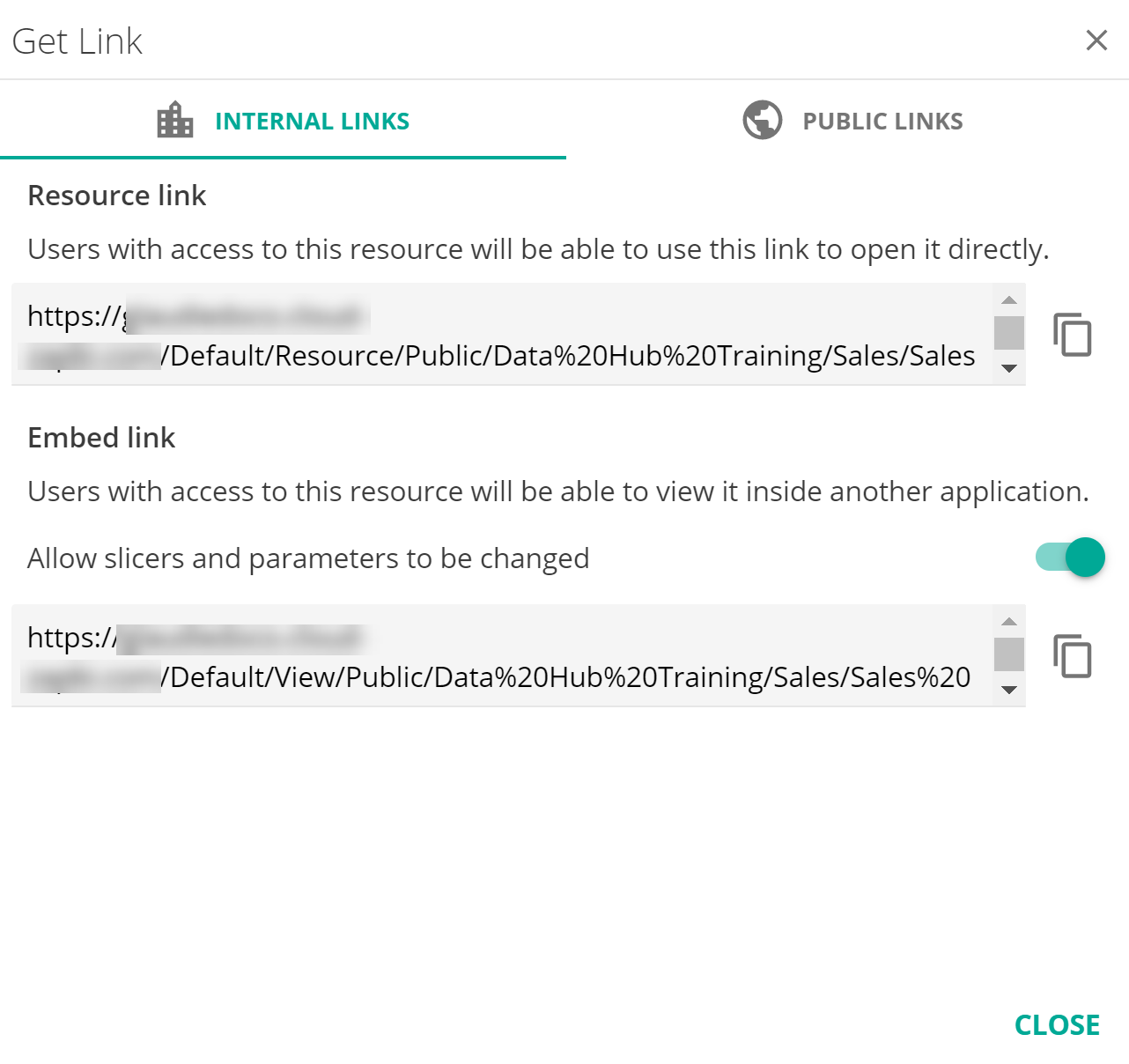 |
Internal Links
INTERNAL LINKS refer to Resource Links and Embed Links. Although the UI has changed, the features are unchanged in this new version of Data Hub.
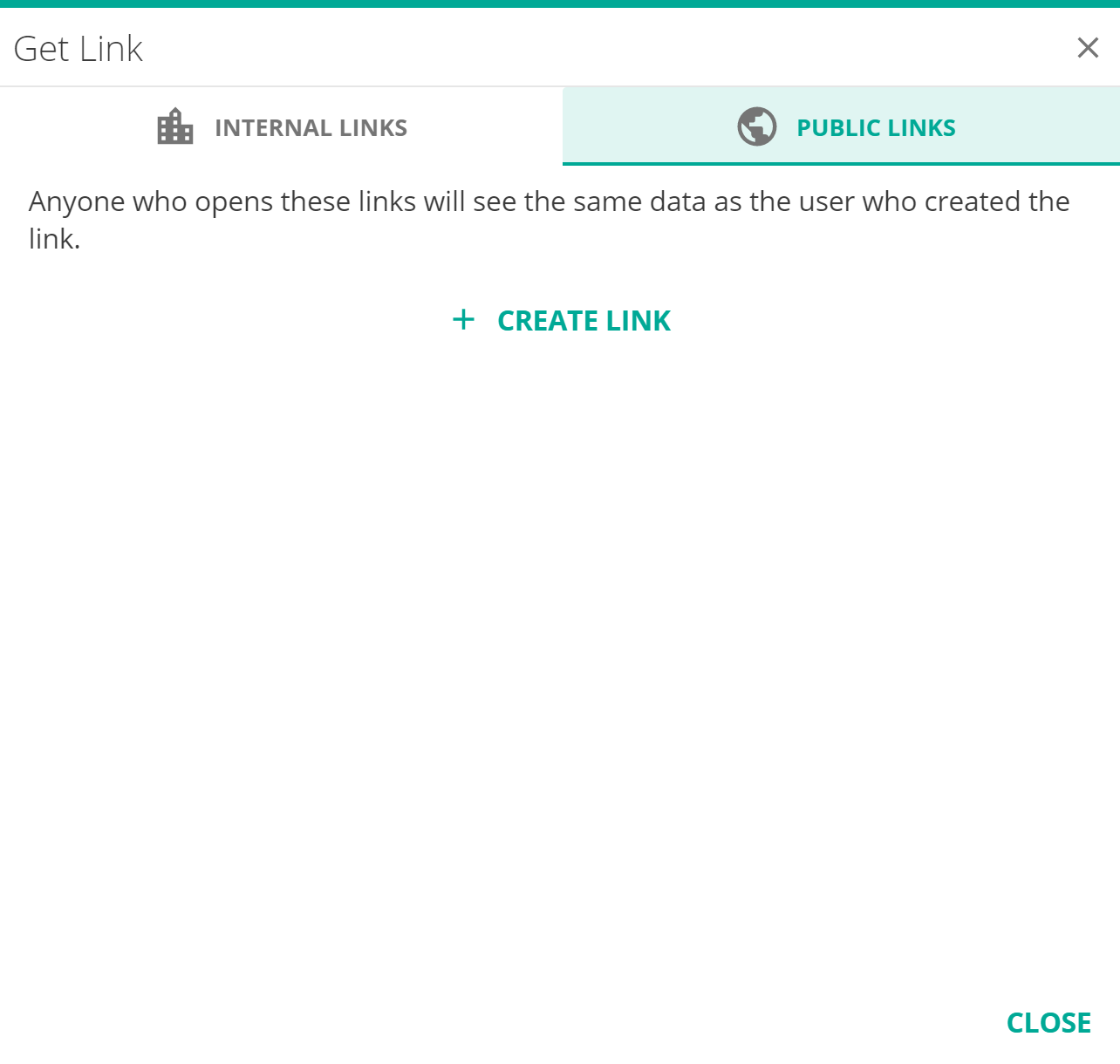
Public Links
The PUBLIC LINKS tab of the Get Link dialog is a new feature in this release. It allows the creation of a link that can be used externally either through a distribution or in an embedding scenario. Public links are unauthenticated-access links, they do not require Data Hub users in order to be opened, and run in a limited security context.
The Public Links feature is License-restricted in Data Hub. It is included by default in any Enterprise (or Premium) plan, and is also available as an add-on but only in Professional (or Advanced) plans.
If your instance of Data Hub is not licensed to use the Public Links feature, then the PUBLIC LINKS tab of the Get Link dialog will be greyed out in the UI, disabled and therefore inaccessible.
Clicking the PUBLIC LINKS tab shows the below screen, and lets you create a new Public Link.
 |
Comparison between the 3 available links.
Resource link | Embed link | Public link | Notes | |
|---|---|---|---|---|
Opens in View mode | No | Yes | Yes | |
Resource navigation available | Yes | Option | No | |
Embeddable resources only | No | Yes | Yes | |
Resource slicing available | Yes | Option | Option | |
Consumer can access the link | Yes | Yes | Yes | |
Consumer user is required | Yes | Yes | No | |
ZAP-Authentication required | Yes | Yes | No | |
SSO supported in embedding scenario | Yes | Yes | N/A | |
Logged-in user security | Yes | Yes | No | |
Resource user security | Yes | Yes | No | |
Pricing | ||||
Per-user licensing/pricing | Yes | Yes | No | |
Feature licensing/pricing | No | No | Yes | |
Available as an add-on | Standard | Standard | Yes | |
Plan limits apply | No | Yes* | *ZAP’s Fair Use Policy applies | |
Availability in Plans | No | No* | *Not available on Standard/Basic. Included in Enterprise/Premium. Available as an add-on on Professional/Advanced. | |
User Interface improvements
The following changes have been made to improve usability in Data Hub.
Dragging objects in placeholders has been improved by showing a | character to help find and indicate where the object will be dropped
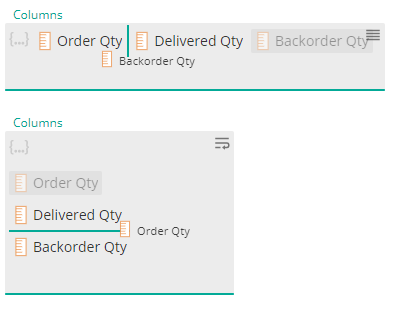
Placeholder toggle switch: In the top right of each placeholder, a new toggle switch is available that will arrange tabs vertically or horizontally. Choosing vertical will result in one tab per row.
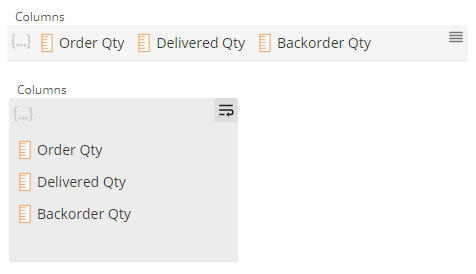
Analysis formatting has been improved with styling like bold column headers, better spacing, text alignment based on datatype and more.
Moving (copy / cut / paste) objects between folders in the resource explorer will show an icon while the action is in progress.
Improved error handling
New Analytics Functions
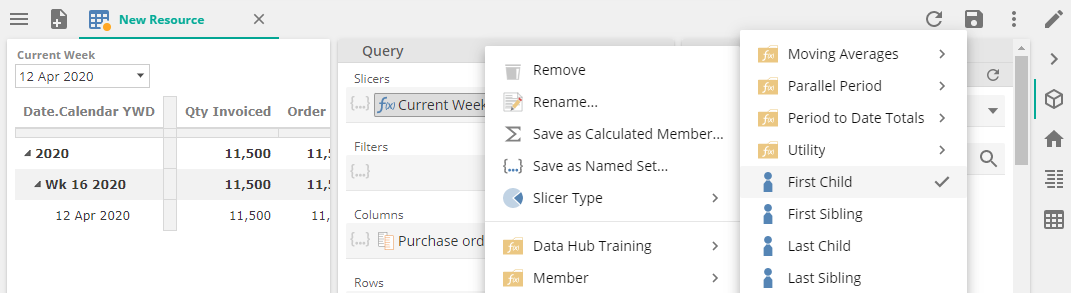
4 new functions have been added to enhance returning specific members from a hierarchy.
These Member functions expect a Member and return the Last Sibling member of that Member (i.e. the last member within the same level as the From member), First Sibling member (i.e. the first member within the same level as the From member), Last Child member (i.e. the last child member of the From member level) or the First Child (i.e. the first child member of the From member level).
These functions are often use with a Date hierarchy, combined with a Current period functions such as Current Month. For example, First Child could be used to return the first day of the Current Month
 |
Modeling enhancements
New connectors and existing connector enhancements
Azure Data Lake
With an increasing demand of big data storage, we introduced the Azure data lake storage data source. Azure data lake storage Get2 with the hierarchical storage option provides a modern way to store and analyze big data blob files. This data source will give you the ability to connect to hierarchical CSV blob files available on Azure data lake storage, and ZAP will automatically merge and flatten the structure for further use in Data hub.
Azure Synapse
A connector to the Microsoft Azure Synapse SQL Pool service, allowing TSQL interfacing.
SAP S/4HANA
A connector to on-premises ERP SAP S/4HANA.
Snowflake
Snowflake is a connector to cloud-based data storage, referred to as datawarehouse-as-a-service, that supports connection to Snowflake on AWS or Azure.
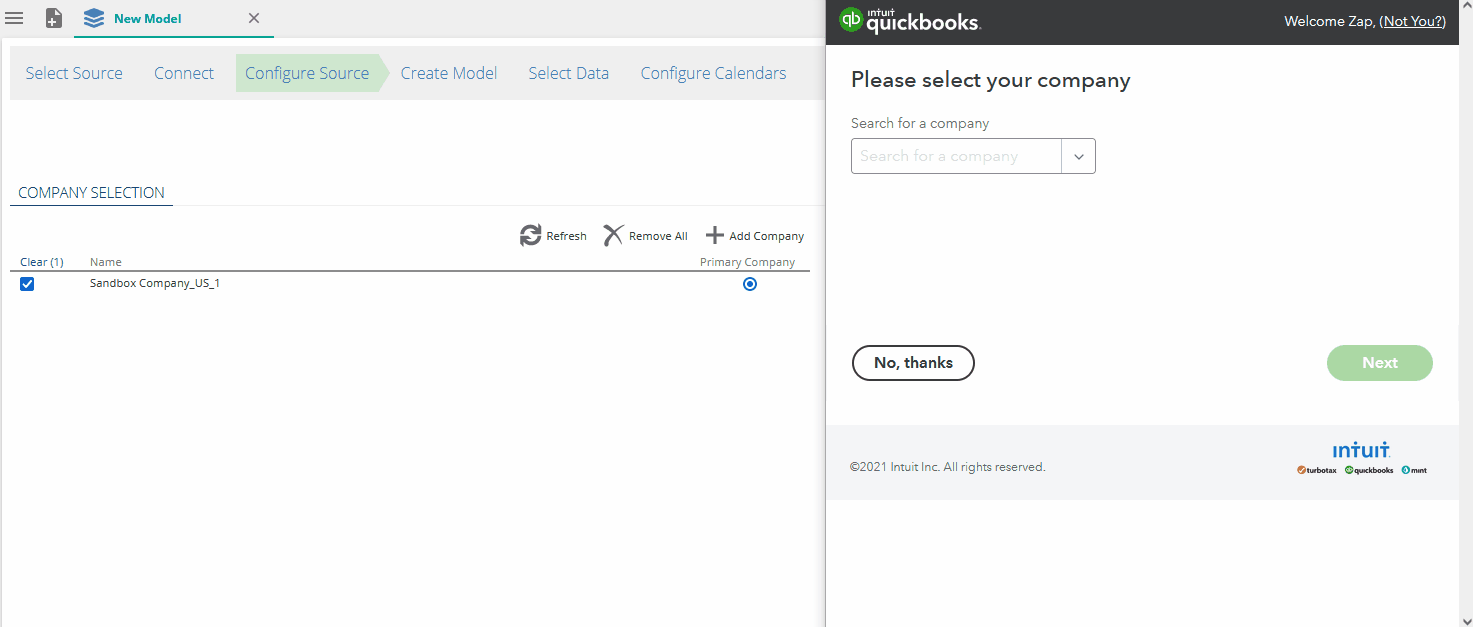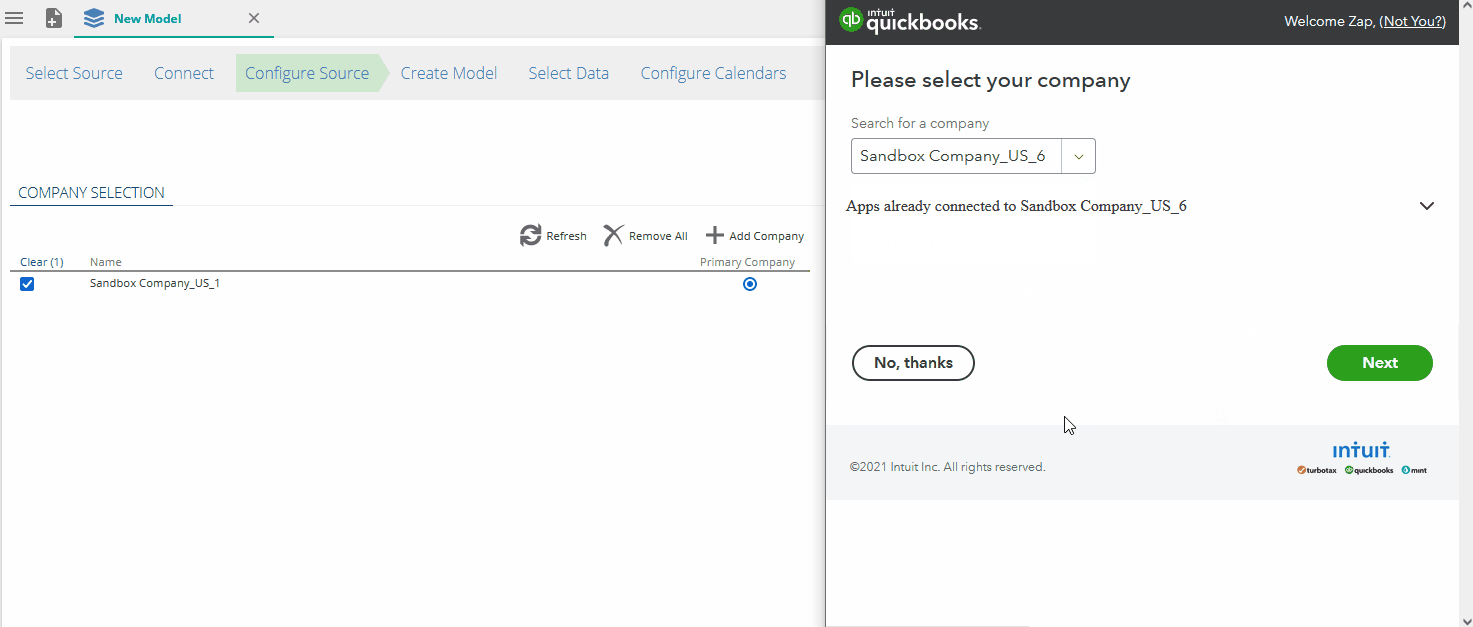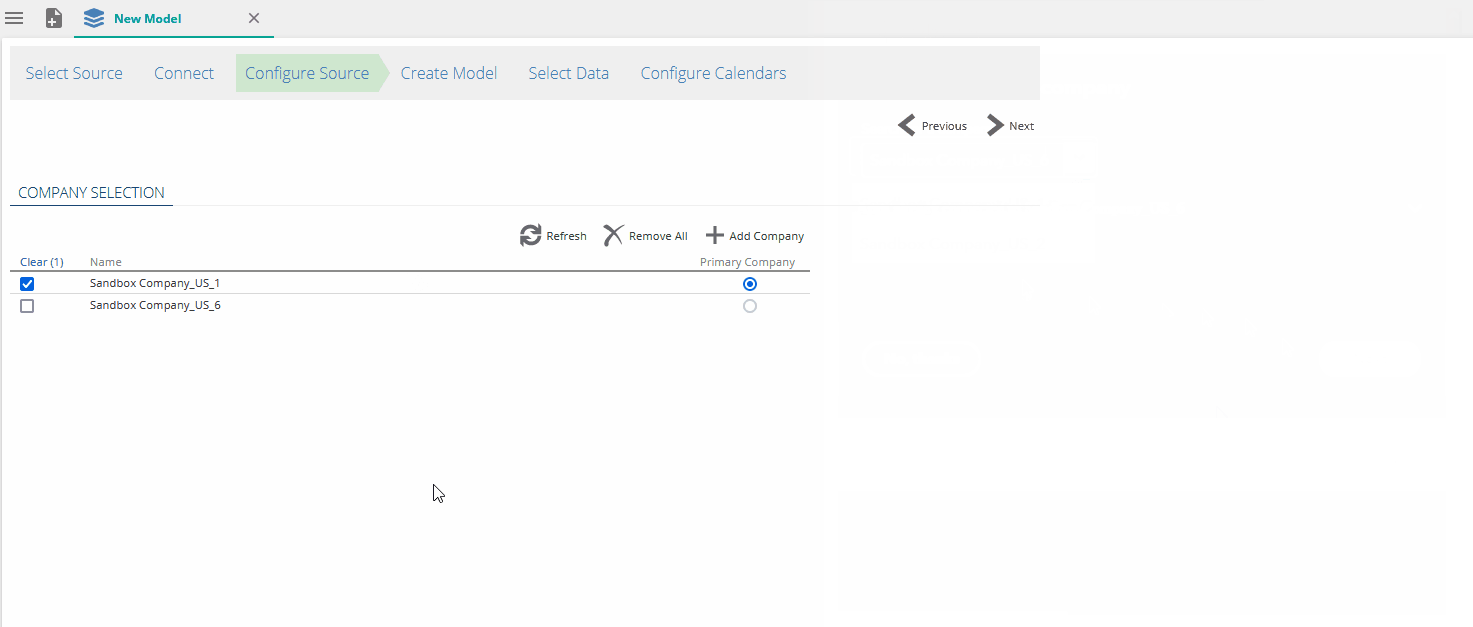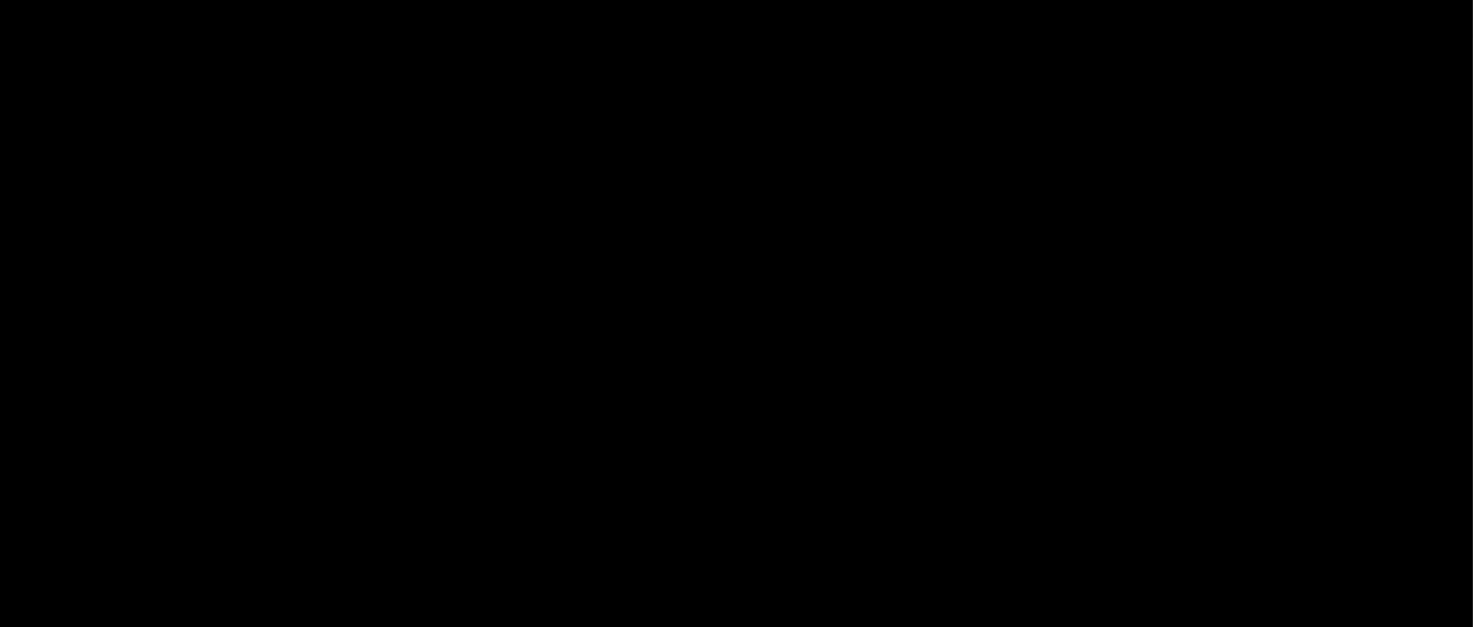
Quickbooks Online multi company support
When first connecting to Quickbooks online, only a single company can be selected in the Quickbooks connection. Data Hub has been updated to offer multi company support. Users are now able to add or remove multiple companies as needed. When a new company is added, the company list will automatically be updated.
Merging of the data will take place once the model is processed.
 |
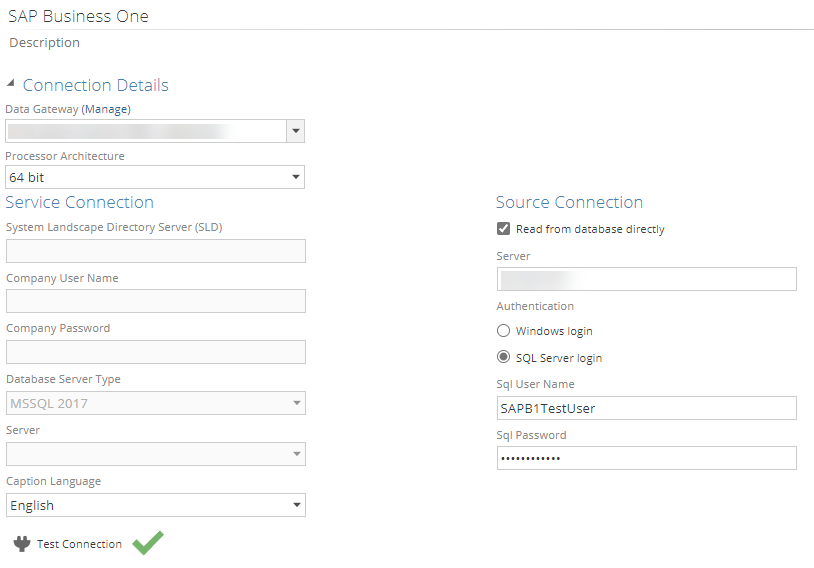
SAP Business One (B1) connector enhancements
Due to several challenges and configuration problems when using the DI API connector and SAP B1 Cloud in the Cloud Control Centre, changes have been implemented to provide a direct SQL Server connection option. At the moment, DI API is available as well as Direct SQL Server connection, depending on the version of SAP B1 that is used. Please refer to the versioning and support information for more detail.
 |
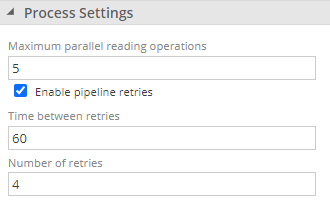
Pipeline retries during model processing
Pipeline retries during model processing of up to 4 times have been introduced. When a model designer or administrator wishes for a model process to retry pipelines during processing, instead of failing immediately after the first failed attempt, this setting can now be configured in the data source Process Settings.
 |
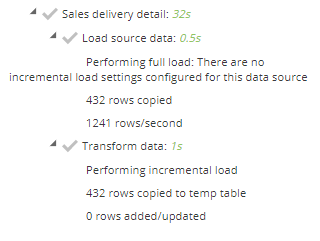
Additional information on the processing tree
Additional information has been added to the model process tree. For every pipeline its possible to see the rows copied, rows per second and Incremental load setting (with a reason for a full load) for the source data, as well as the transform data. "Synchronized reporting calculations" now shows under the "Process cube" node.
 |
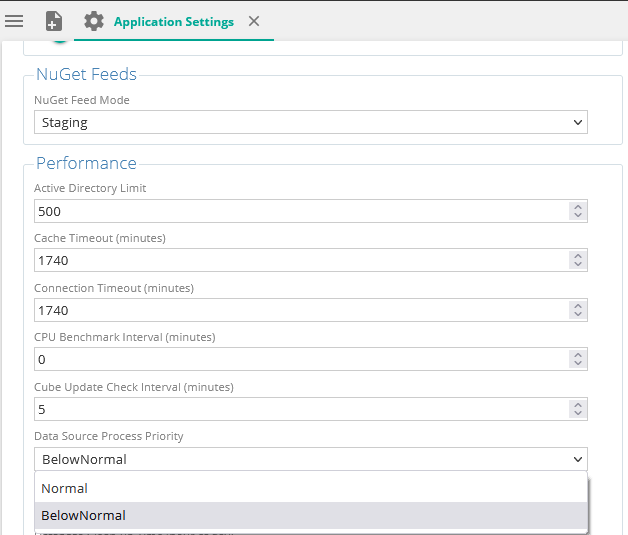
Data source processing priority setting
A new configuration setting has been added for data source processing priority. The setting has two values: "Normal" and "Below normal" . The new default setting of "Below normal" will create data source processes with reduced cpu priority, to avoid UI instability.
It can be changed back to normal which was the default setting in the past.
Note
This setting can only be changed by an administrator.
 |
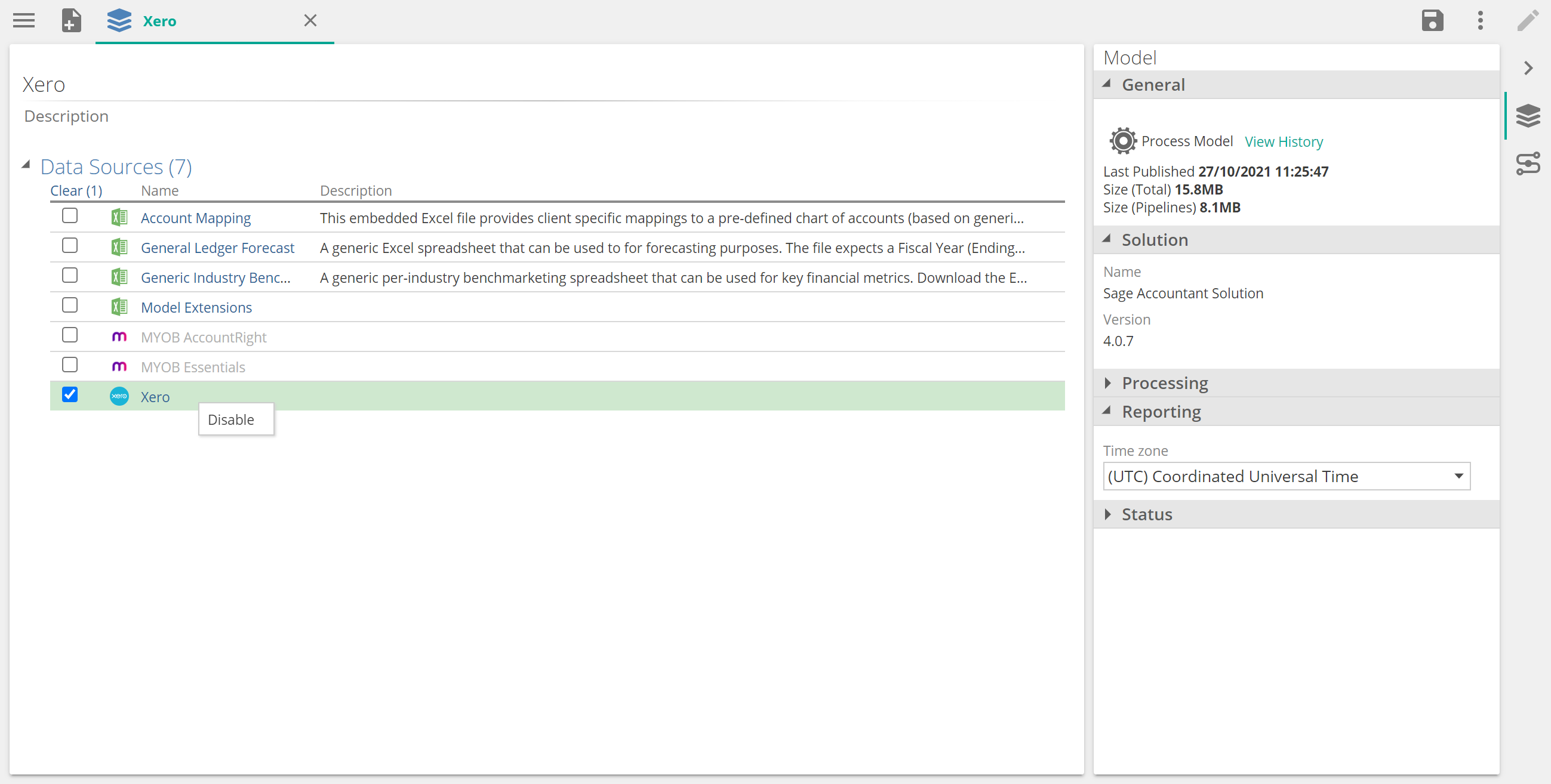
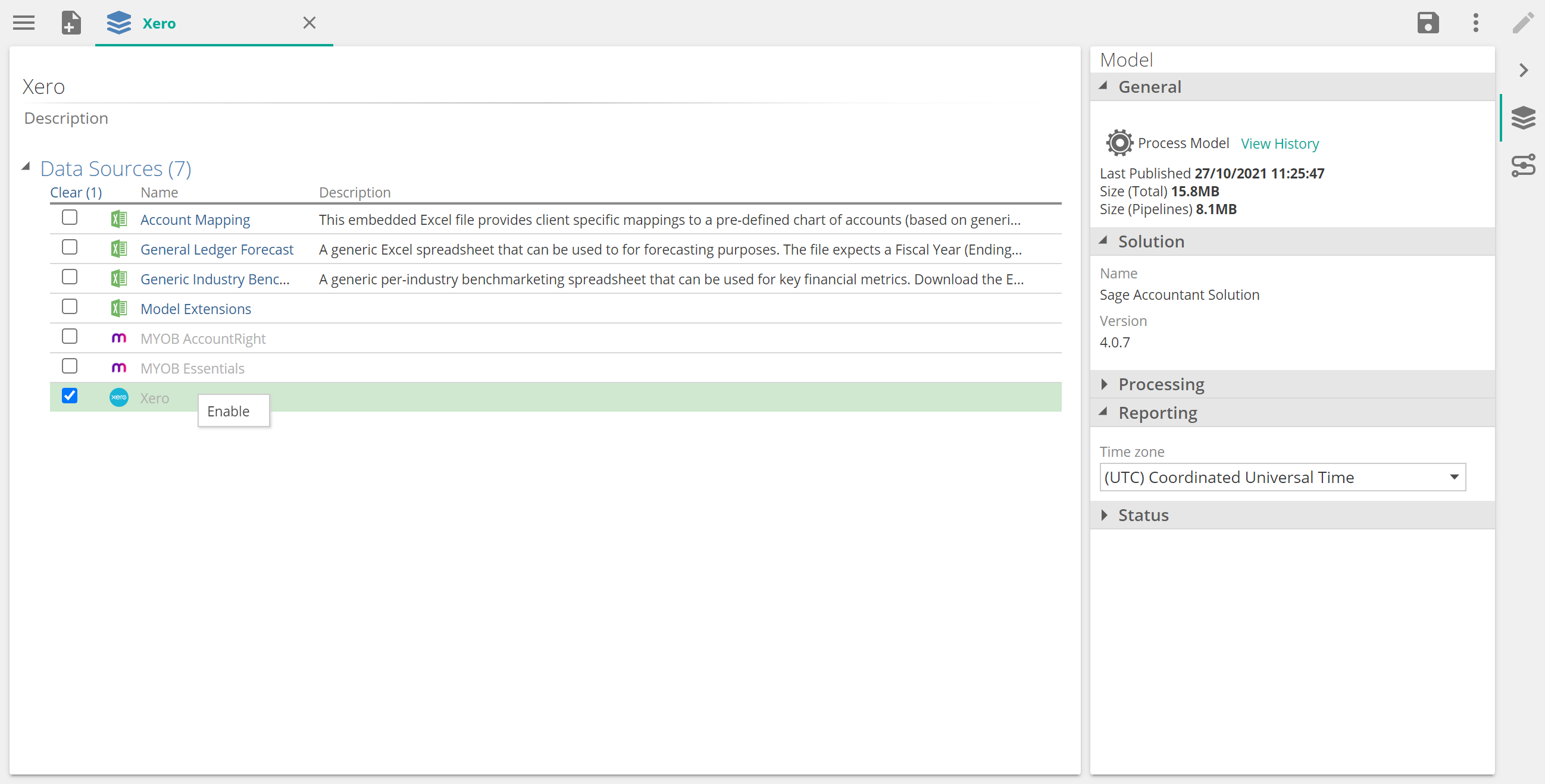
Data source disabling/enabling
A new option to disable a datasource has been introduced. This offers the flexibility for Administrators or Model Designers to work with a limited number of datasources in their Accountant Solution, based on your clients’ accounting software. To disable a datasource, simply right click the datasource of your choice, select the Disable option then Save your changes.
 |
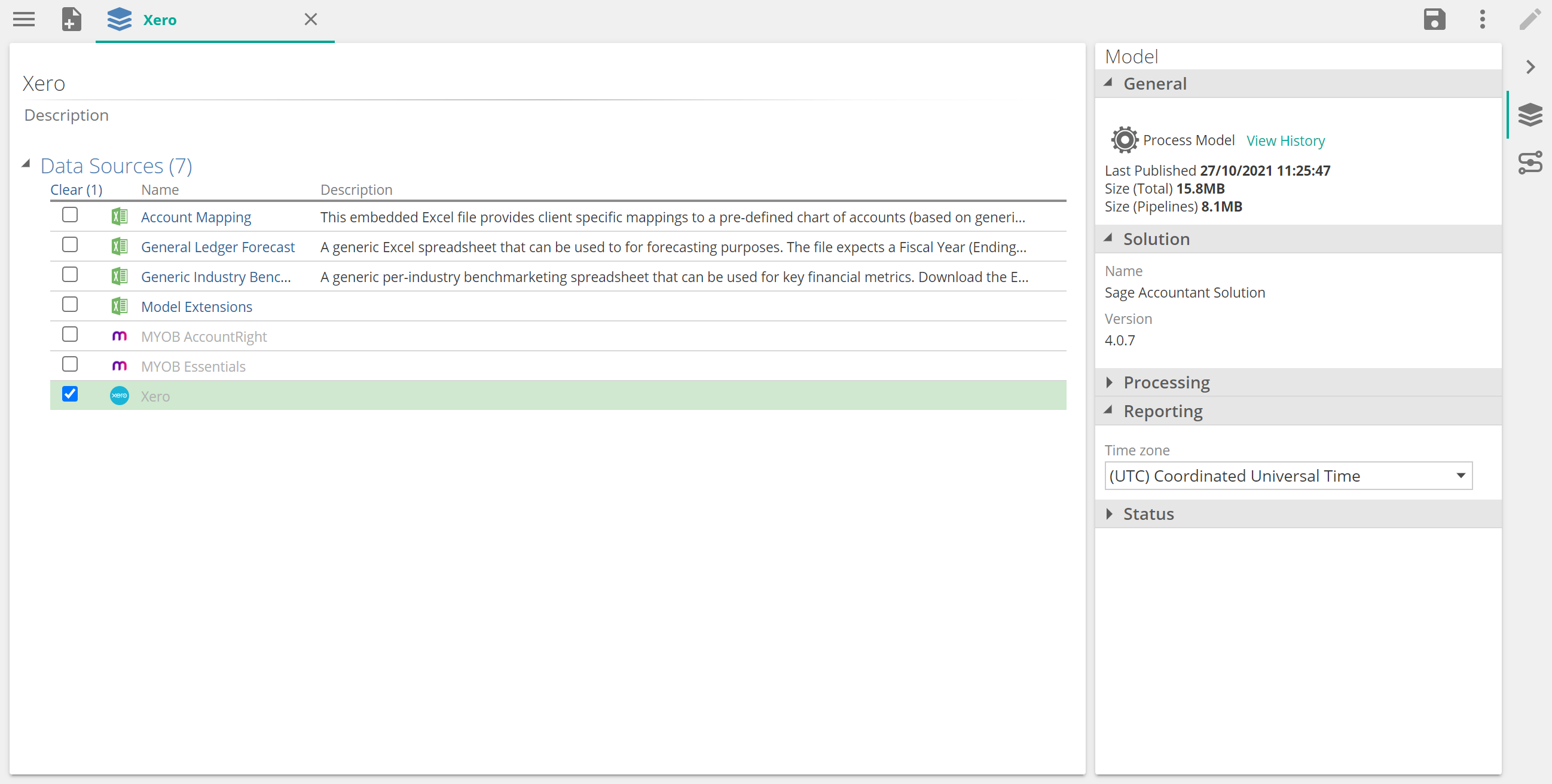
Once a datasource is disabled, its name is greyed out and it cannot be configured anymore.
 |
You can enable a disabled datasource by simply right clicking the datasource and selecting Enable
 |
Column store indexes
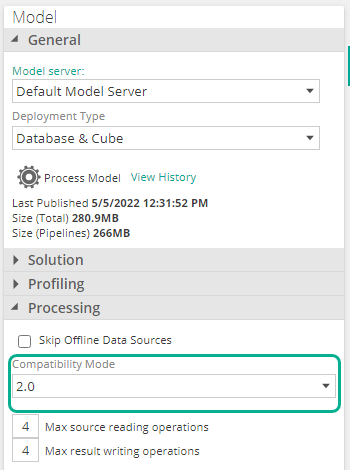
Data Hub now automatically creates clustered column store indexes (or sometimes referred to as columnar indexes) behind the scenes. In most scenarios, you will notice a reduction in datawarehouse size thanks to better data compression. Column store indexes have many benefits and should improve data migration time, as well as various other transformations.
To enable column store indexes to be created, set the Compatibility Mode to 2.0 on the Model properties pane, in the Processing section.
Additional Semantic Layer Storage: Tabular
ZAP is adding support for a new semantic layer type: Tabular, which is in addition to the currently-generated Multidimensional semantic layer type (also commonly referred to as cubes).
This added type manifests as two new Cube environment types in a Model Server resource, namely: SSAS Tabular when deployed on SQL Server on-premises, and Azure Analysis Services when deployed to a proprietary Microsoft Azure subscription.
In version 10.1 on-premises, and cloud versions of Data Hub, from the April 2022 update (Release 56), this feature is available as a Beta release.
The FAQ's below will assist in your decision to determine whether this new engine type is appropriate for use by your organization.
Tabular FAQ's
Important
This release ONLY supports modeling scenarios, not reporting scenarios from ZAP.
What is SSAS Tabular, and what are the differences with Multidimensional and Azure Analysis Services?
SSAS Tabular is a native column-store based storage engine, introduced in SQL Server by Microsoft in 2012, and perfected ever since. It is the engine that powers data sets in Power BI. In recent years the Tabular engine was also released as an enterprise managed service in Azure, called Azure Analysis Services. Multidimensional engine has remained an on-premises SQL Server engine, only.
While Tabular and Multidimensional engines are similar functionally, there are notable and important differences in terms of their hardware requirements, compression levels, querying methods, programming languages, and also with their respective modeling requirements.
Why is ZAP releasing this new semantic layer type?
ZAP did not and does not require supporting Tabular for its own reporting and visualizations, but it is a requirement and expectation for users of Power BI, or organizations who leverage ZAP Data Hub as an integral part of their BI topology in Azure. Only the Tabular engine is supported as a managed service in Azure.
Am I licensed to use this new type?
Yes, Tabular engines are available as an option in Model Server resources starting from Data Hub 10.1 or Release 56 in the cloud.
Do all Data Hub features work with the new Tabular engine type?
Most data modeling features work with Tabular. However, it is critical to note that reporting and visualization resources of Data Hub do not and can not query a data model generated on SSAS Tabular or Azure Analysis Services, yet.
What are the scenarios for using the new Tabular types?
If you use or intend to use the prebuilt ZAP Analytics or create new reports, visualizations and dashboards from Data Hub, you do not have and should not use the new Tabular engine. Data Hub does not support querying a ZAP-generated Tabular model yet.
The main scenarios for using this new Tabular engine, are:
If you already have investments in Tabular models, and have a SQL Server instance of Analysis Services Tabular, or organization staff trained on this technology
If your organization uses Power BI.
If your organization would like to govern their data and materialize their semantic layer in a Tabular model rather than connecting Power BI to the ZAP-generated datawarehouse.
If your organization plans to leverage Azure Analysis Services in their Azure subscription.
I have an existing data model generating Multidimensional models, can I upgrade to a Tabular data model?
Yes. Data Hub will create a backup resource too.
What is the minimum required compatibility level on-premises?
ZAP requires Analysis Services compatibility level 1200 or higher. To this date, it is the minimal supported compatibility level of Azure Analysis Services.
Do ZAP pre-built solutions work with the new Tabular Types?
Some of the design principles of Tabular models are different compared to Multidimensional models. For example, a Tabular model does not differentiate between a dimension or a fact table, even if it is a best practice to model data as star-schema, it does not support the concept of attribute keys and attribute names, it requires ordering name columns by the key which is the opposite of a Multidimensional model, and requirements for modeling data is slightly different in order to be optimized, parent-child hierarchies are also not natively supported by a Tabular model.
Therefore, an upgrade path from a data model built in Data Hub with a Multidimensional model output is not simple. But in order to facilitate such upgrades to Tabular, Data Hub v10.1 and release 56 in the cloud have introduced upgrading to Tabular.
Limitations
Row or object level security is not available. Due to the structure of data stored in columns and not rows, this functionality is not available.
Data Hub analytics for tabular is not available in this release.
Many-to-Many relationships in tabular is not supported.
Tabular doesn't allow Bi-directional relationships.
No validation on DAX measures
New Validation Errors
The following new validation errors will be present for tabular modeling:
Relationships with Ambiguous paths
Relationships that create cycles
DAX measures that doesn't have a name
DAX measure names that are not unique
Modeling differences
Model design in tabular differs significantly from multidimensional modeling. To get started and understand the differences read more about Getting started with Tabular Modeling
API integrations
New APIs are made available for developers to build App integrations with Data Hub.
Model Data API
The Model Data API enables interfacing with datawarehouse data through a new dynamically-generated OData API.
Model Process API
The Data Model Process API (HTTP) enables the processing of data models (full model or per pipeline) programmatically, without using the UI.
Changes of behavior and deprecated features
D365 Finance and SCM datasource Source SQL pipelines
Although the flexibility of the ZAP connector for Dynamics 365 Finance and SCM allowed querying the Dynamics 365 service using SQL in Source SQL pipelines, this functionality was never intended to be used in customization scenarios in Production. ZAP is to deprecate the Source SQL Pipeline option for Dynamics 365 Finance &SCM connector, in order to improve the stability of Data Hub and ensure that it cannot negatively affects the Microsoft Dynamics 365 platform.
This deprecation manifests in two ways:
The option to create a new Source SQL pipeline has been disabled. The Source SQL Pipeline button will be greyed out and unavailable (applicable from Data Hub 10.1 and the May Cloud release).
A new checkbox named Enable Source Query has been added to the Dynamics 365 Finance & SCM connector (applicable to every version of Data Hub)
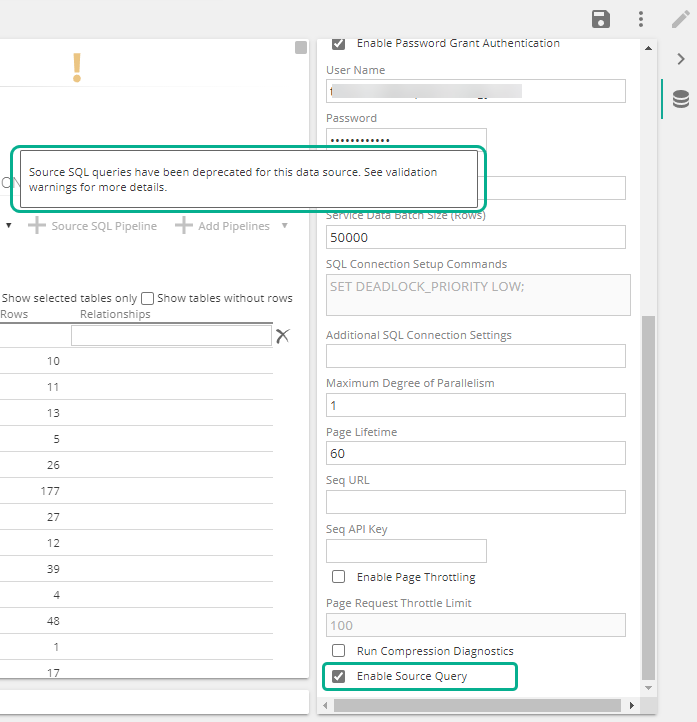
This option is disabled by default for new connections or solution deployments, but will be checked for upgraded data models. When this Enable Source Query box is not checked, pipelines that sources data from a Source SQL query, or pipelines that have a dependency on those pipelines will display a new warning.

Important
ZAP plans to enforce this new Enable Source Query option and completely remove support for Source SQL pipelines by November 2022, affecting any existing Source SQL pipelines in Dynamics 365 Finance & SCM data models. ZAP Support will be in touch with any affected customer.
Microsoft Graph support for Azure AD authentication
Microsoft is deprecating the current Azure Active Directory Graph API that was used to connect and configure Azure Active Directory in Data Hub as the authentication provider.
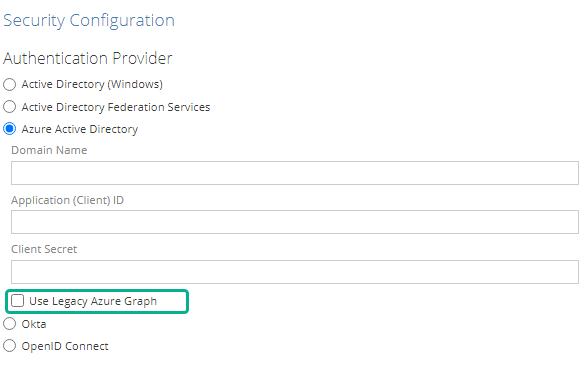
ZAP is adding support for a new format: Microsoft Graph API in Data Hub 10.1. This new API requires reviewing the Application Permissions of your Azure AD Application by following the below steps:
Navigate to: API Permission>Microsoft Graph>Application Permissions
Add: the Directory.Read.All permission
Then On the Data Hub Authentication screen of the Settings menu, ensure that the Use Legacy Azure Graph box is not checked.
On-premises customers who currently use Azure AD should upgrade Data Hub to version 10.1 and review their authentication settings as soon as possible in order to prevent any interruption.
Corrected Defects
This Knowledge Base article provides a notable subset of the defect resolutions.