Processing and publishing
Overview
The two main tasks that occur when preparing a model for use are processing and publishing.
You are able to process a model, individual pipeline, or a group of pipelines. In addition, if any changes have been made that need publishing updates, you can choose whether or not to include those updates in your process.
You can add model process configurations, which allow you to define scheduled background tasks to periodically refresh the model or pipeline.
Processing settings
Processing involves creating a physical structure in the data warehouse that matches the logical structure of the model. The end result of the process action is a warehouse.
If you make a minor change to a model that has been previously processed (such as altering a calculated column), processing the model again (via the Process button) reprocesses only the affected pipelines, rather than the entire warehouse, increasing the speed of the overall operation.
A process action is not always successful, as there may be errors in the model that prevent creation of a valid cube. In addition, any changes to security are updated every time a model is processed.
Set model processing properties
Processing properties allow you to:
Skip offline data sources.
Control parallel pipeline processing.
Define the model owners.
These settings apply only to the warehouse (not the cube).
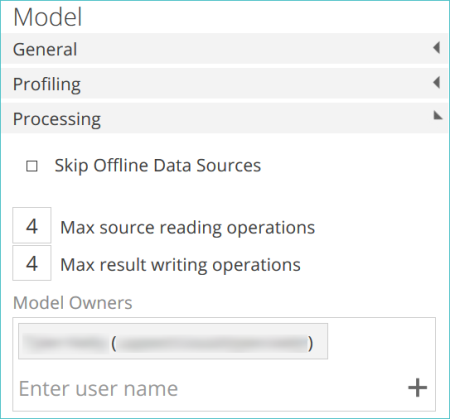 |
Skip offline data sources
Offline and inaccessible data sources will be ignored when this option is selected. The model will be then processed without the updated data from these sources.
This option does not affect the requirement for new data sources to be accessible when:
The data source is added to the model.
The model is first processed after the data source is added.
Warnings indicating that data sources have been skipped will be shown:
On the Model Panel under Status at process time.
On the Background Tasks List, when hovering over items in the Issues Column.
Max source reading operations
This is the maximum number of pipelines that will read from their data source at the same time (irrespective of which data source they come from).
If you have a model that sources data from many different servers, (particularly if the data sources are web-based) increasing this value may improve performance.
Alter this setting in conjunction with the Maximum parallel reading operations setting for individual data sources to allocate more threads to data sources that will benefit the most (e.g. web-based data sources).
Note
If the total number of threads specified (in the Maximum parallel reading operations property for all data sources) exceeds the Max source reading operations setting, the thread count for each data source is reduced proportionally to match the Max source reading operations setting.
Max result writing operations This is the maximum number of pipelines that will write their result (as a materialized warehouse table) at the same time. If you have powerful hardware for your warehouse, increasing this value may improve performance. If you have limited hardware resources, decreasing this value may improve performance.
Model Owners This tag control allows you to define the user who owns the model. Model owners will receive an email if the processing of the model fails for any reason (when using a process configuration). You can specify a single owner or multiple owners. By default, the user who created the model is the owner (the user name is concealed).
Publishing settings
Publishing is the act of saving a version of a model so that it can be reused in the future. A model that does not process successfully will not be published.
Publishing a model overwrites the previously published model. The last published model is used for model process schedules and may be used when manually processing the model in future. This behavior guarantees that model process schedules will be completed without error.
During the processing of a model, the publish task is represented by the Update Published Model step displayed in the Status area of the Properties panel.
Note
Publishing a model is different from saving it. Saving a model saves any changes made to the model's "working copy" (the current state of its pipelines, columns and hierarchies). Publishing a model saves a separate copy of the model to the "working copy". The essence of publishing a model is that it saves a copy of the model that just processed successfully, and is therefore guaranteed to process again successfully.
Process configurations
Model process configurations are added to a model to define how it is processed.
You may define a configuration to process just a particular group of pipelines, such as the pipelines relating to the finance area only.
Or you may create a process configuration that performs a full load of the data warehouse tables (which needs to be executed periodically to remove deleted rows).
Process configurations may also be used to set up scheduled background tasks to periodically refresh the model.
Note
By default, any new process configuration automatically performs a full process.
Pipelines - By default, all pipelines are processed (using the All tag). However, you can specify individual pipelines for processing using this option.
Database Scripts - By default, all database scripts are processed (using the All tag). However, you can specify individual scripts for processing using this option.
Incremental Data Load - This allows you to specify how data sources and pipelines are updated. The available options are similar regardless of whether you are processing models or pipelines.
Specify publishing options
If any publishable changes are present, you can use the Publish changes check box to determine whether or not you want to publish the changes.
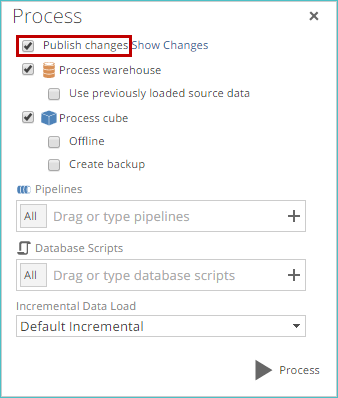 |
View the changes by clicking the Show Changes link near the top of the Process screen.
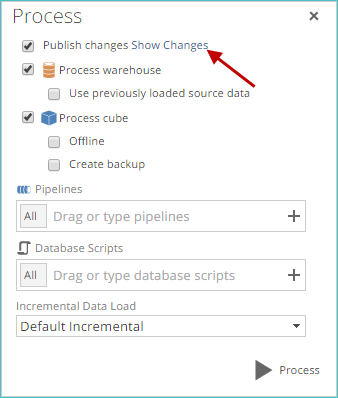 |
When this link is clicked, a Comparing tab appears, showing you the changes.
Important
When processing the model for the first time after it is created, you must publish the listed changes. The Publish changes check box is dimmed (grayed-out) in this case, so that you cannot choose to not publish the changes. This behavior only occurs the first time you publish the model.
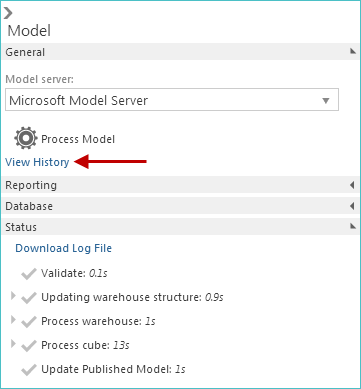
View processing history
To view all past and currently-running process operations, click the View History link (adjacent to the Process Model button on the Properties panel). The most recent publish data and time is shown immediately below the button.
 |
Note
The View History link is accessible via the model properties panel and the Properties panel for an individual pipeline. Clicking the link in the pipeline Properties panel opens the information for the model of which the pipeline is a part, not just the individual pipeline.
Once clicked, the information for the current model is displayed on a new Manage Background Tasks tab. The displayed information includes successful processes, failed processes, and running processes (if the model is current being processed).
Previously published models
If errors occur during model processing, and the model was previously published successfully, the previously published version can be used to successfully process the model.
In the following example, several errors appear in the Status area of the model Properties panel following processing.
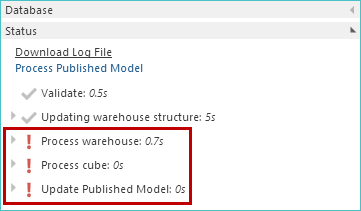 |
To reprocess the model, using the previously published version, simply click the Process Published Model link.
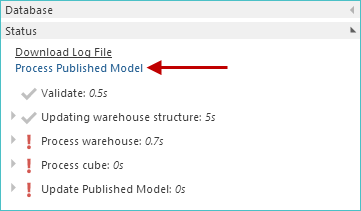 |
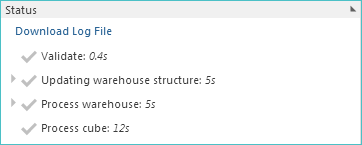
The model is reprocessed, and all errors are resolved.
 |
Set standard process options
The following settings are always available, regardless of whether you are processing a model, individual pipeline, or a group of pipelines. If you are using a process configuration, some settings are not available, as designated below.
Process warehouse - If you want to include the warehouse in the process, click this check box, and specify the following related options:
Migrate source data - This setting specifies whether or not source data is migrated into the pipeline staging tables. If unchecked, existing data from the last time the model was processed may be used. This saves time when testing pipeline behavior. The setting is selected (checked) by default.
Skip previously migrated pipelines - This setting is related to the Migrate source data setting. When selected, pipelines that have data records from a previous process will not be refreshed from the data source. If you have this setting checked and a subset of the pipelines have previously been migrated, the migrated pipelines will not be refreshed while all other pipelines will be. The setting is cleared (not checked) by default.
Important
This option is not included with process configurations.
Perform Transformations - When selected, each pipeline will be materialized as a table in the data warehouse. Both views and warehouse tables will still be published in the warehouse, as this setting only affects whether the warehouse tables are processed. The setting is selected (checked) by default.
Exclude dependencies - When selected, only selected pipelines and database scripts will be processed. Pipeline and database script dependencies will be ignored. The setting is cleared (not checked) by default.
Note
You can view the a pipeline's processing dependencies by examining the Processing Dependencies area on an individual pipeline tab Properties panel.
If pipeline A has a lookup to pipeline B, and this setting is selected (checked), only pipeline A will be processed.
Incremental loading
This feature of data sources and pipelines may speed up loading information into the data warehouse. Only new or updated transactions are copied rather than the entire source table.
For incremental loading to work for a given table, a column must be present in a table which allows rows added after the last incremental update to be identified. For many databases, this is a time stamp column.
In other databases, there may be another column that can be used. Such a column must have entries that are monotonically increasing (the value for each row is greater than or equal to the value for the previous row) so that rows added after a given row can be identified. The values in the column do not have to be unique.
Typical columns that may be used are item codes, invoice numbers, employee numbers, or other types of key columns, or batch identifiers – as long as they are monotonically increasing values.
Incremental loading behavior
Depending on the data source, incremental loading may be handled differently. Most data sources (e.g. CSV files), are fully loaded into the data warehouse by default.
However, if you can identify a column in some or all tables that can be used to determine which rows are new, you can manually customize the incremental loading settings to use it. Most data sources contain suitable time stamp or other columns that can be used to control incremental loading.
Data sources created as part of a package import may default to incremental updates.
Incremental loading interaction (Models, Data Sources, and Pipelines)
When processing a model, you can determine the type of incremental data load that will take place. You can specify a full (non-incremental) load, a regular incremental load, or a quick incremental load. By default, a regular incremental load adds new data and updates existing data, while a quick incremental load only adds new data and does not update any existing data.
Quick incremental loading may be useful for data models that require hourly addition of new transactions (where changes to existing transactions are rare and will not affect the accuracy of the resulting cube).
This incremental behavior can be customized at both the data source and pipeline levels (allowing you to specify the exact behavior of both a regular incremental load or a quick incremental load). The following settings can be selected:
Add and Update - The default behavior for a regular incremental load. All new data and any updates to existing data are added to the warehouse.
Add Only - The default behavior for a quick incremental load. Only new data is added to the warehouse. No existing data is updated.
Data source level - You specify exactly what incremental behavior is used on pipelines coming from the data source during both incremental load types. These settings are then propagated down to each pipeline originating from the data source.
Individual pipelines - You can specify incremental behavior for individual pipelines (which allows you more control if one specific behavior setting is not appropriate for all data source pipelines). Customized individual pipeline settings override data source-level settings.
Incremental data load setting
The following options are available:
Default Incremental - The regular incremental process, which allows you to load both new and updated data to the staging database. It is designed as a more inclusive process option than Quick Incremental but typically takes a significant time (many minutes or hours) to execute. When this option is selected, all data sources and pipelines in the model automatically map to the Add & Update incremental load option.
Quick Incremental - This incremental process allows you to only load new data to the staging database, and process the model with only this newly added data. It is designed for firms that have large volumes of transactions at all times of the day and want more frequent updates (such as hourly updates) that can often be performed in minutes. When this option is selected, all data sources and pipelines in the model automatically map to the Add Only incremental load option.
Full Refresh - A full (non-incremental) data refresh is performed. This option is slower (often taking several hours), but may need to be performed periodically to ensure integrity for some data sources. For example, where incremental delete is not performed, depending on the source database structure, deleted rows may affect the accuracy of reports produced from the cube. This type of process is often performed overnight or during non-peak times.
Remove individual pipelines
If you have added a pipeline to the Process screen (or to the Properties panel), but you decide that you do not want to process it, you can remove it using the small "x" button that appears when you hover over the pipeline entry in the corresponding text box.
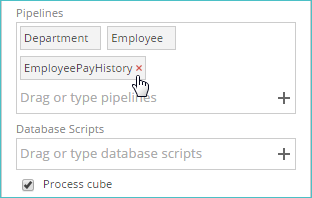 |
Process specific database scripts
You can process individual database scripts or groups of scripts, instead of processing all database scripts (as when an entire model is processed).
Two distinct type of database script selection methods can be used. You can open individual scripts and process them, or you can specify the scripts directly on the Process screen.
When processing database scripts, only affected measure groups and dimensions are processed, as opposed to the entire cube. This behavior increases the overall speed of script processing.
Process dependencies
You can view processing dependencies for the current pipeline by examining the new Processing Dependencies area of the pipeline Design panel. A pipeline depends on another pipeline if there's a lookup, warehouse pipeline, calculation, or SQL step in the pipeline that references the other pipeline.
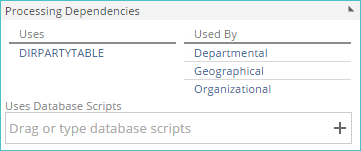 |
The following information is displayed:
Uses column - A list of other model components that the current pipeline relies on when it is processed.
Used By column - A list of model components that rely on the current pipeline when they are processed.
All listed model components (in both columns) are also links, which, when clicked, open the corresponding item in a separate tab.
Uses Database Scripts - Specify the database scripts that must be executed before the current pipeline can be processed. The actual moment of script execution in the overall process depends on the individual script's Type setting.