Relationships
Data models in Data Hub store information in a data warehouse, (based on a star schema design) and produce a semantic layer, which support in depth reporting.
Details on star schema modeling and relationships are described in Star schema modeling
Semantic relationships
When the model is created, relationships are added between pipelines in the model. These relationships come either from the source database structure or metadata, where available (for sources such as SQL Server) or from a profiling algorithm, which creates relationships based on field names and comparison of data from possibly-related fields.
Semantic relationships will be present in the data warehouse, and also between the appropriate facts and dimensions in the Semantic model, so they can be used to create reports. On the Properties of each relationship, the Type can be set in a drop down in the General section.
Relationships for each pipeline can be seen on the RELATIONSHIPS pipeline tab. This tab shows Semantic relationships as well as Lookup relationships. Lookup relationships do not have the blue icon in the table list.
 |
Semantic Layer only relationships is visible on the Relationships section of the model screen.
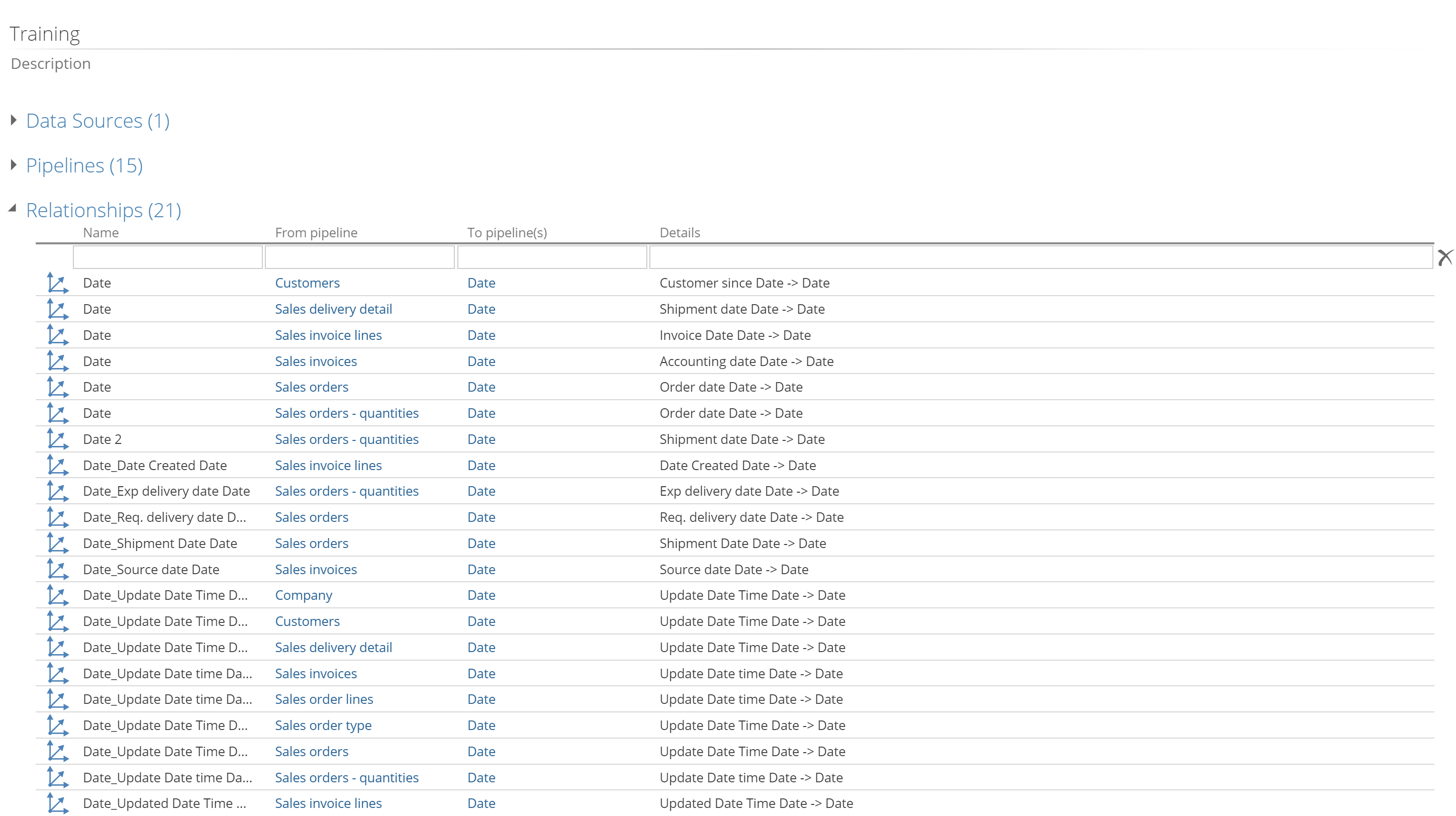 |
Mapping relationships
A mapping must be added for each field in the related pipeline that is marked as a key field. In many cases, the relationship will be between a single foreign key field in the current pipeline and a single primary key field in another pipeline.
If the For reporting check box in the General section of the Design panel is cleared, the relationship is used only to support lookup columns in the warehouse, and is not used in the cube. In this scenario, the relationship may be more flexible than a relationship used in the cube. Two additional controls, Not and Operator, appear in the Mappings section.
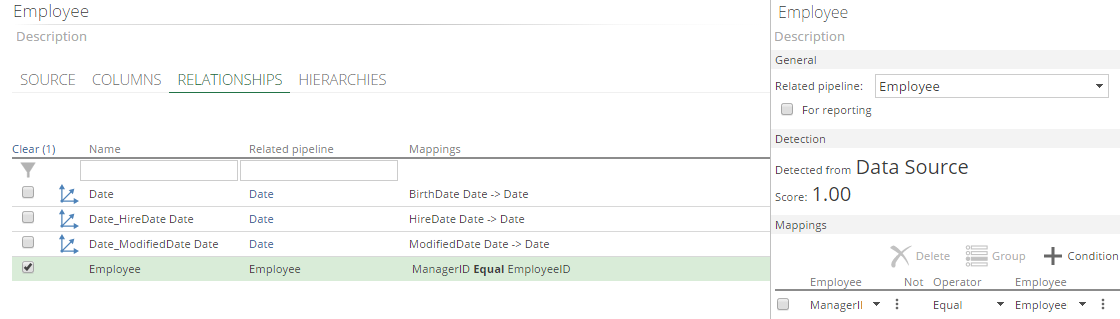 |
Inactive relationships - Tabular modeling only
Semantic Relationships can be set to be inactive within a tabular model. This strategy is intended to avoid the creation of ambiguous paths, while you may still need this relationship in the mode.
Setting a semantic relationship to inactive, results in it not used by default and thus not creating ambiguous paths in the model. While an inactive relationship on its own has little value it can used in the calculation of a DAX measure via the USERELATIONSHIP function. This function effectively activates the relationship during the calculation of that specific measure.
Read more about using inactive relationships in the USERELAITONSHIP function
Role-playing relationships (Duplicate relationships)
It is often necessary to create two or more relationships that map between the same two pipelines. Dates are a good example. Delivery date, Order date, Receipt date, invoice date are just a few that could exist on the same pipeline. In order to correctly report on all these, you want different dimensions for each of them in the cube, which requires a relationship for each.
Example
In this example, two relationships from Purchase order line exist to the Date pipeline: one for the Order date, and one for Actual Delivery Date. These are duplicate relationships to the same Pipeline and will act as role-playing dimensions in the cube. A third relationship will be added for Update Date.
A role-playing dimension is like a copy of another dimension, that plays the role of allowing another, different relationship to be made to the dimension.
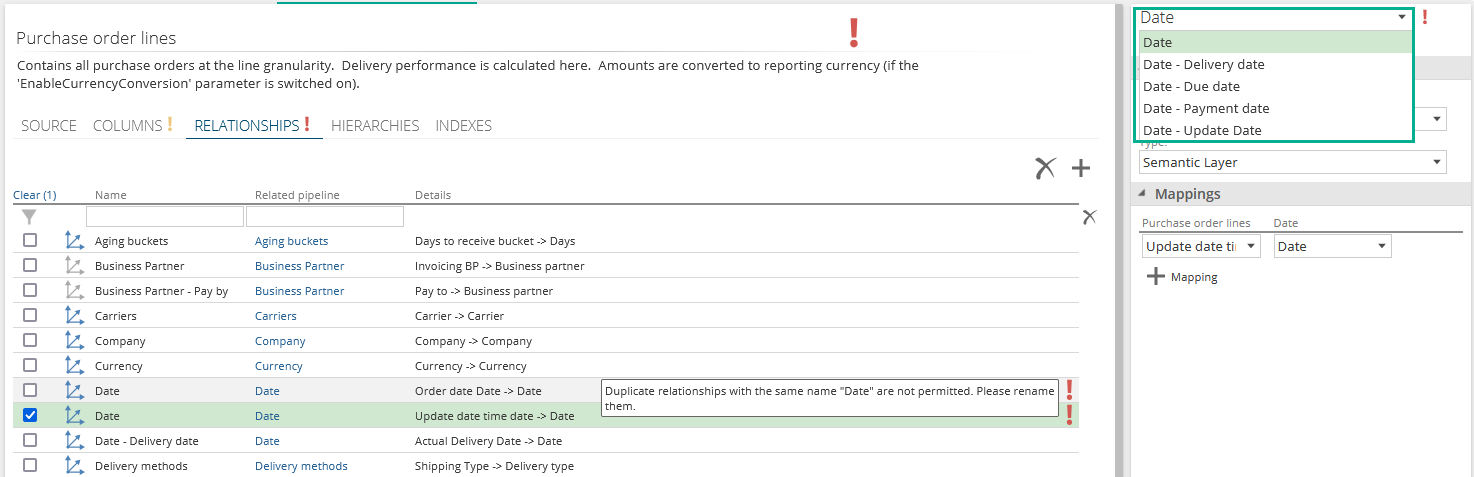 |
NOTE the error message indicating a duplicate relationship when you first add it.
Rename the relationship so it has a different name from the existing relationship. In this situation, the Relationship name box appears as a drop-down list as seen above.
The drop-down list displays all the role-playing dimension-type relationships already available in the data model. If the duplicate relationship you are creating is for the same purpose as a duplicate relationship already created for another pipeline, you can select that relationship name. Doing this means that the two duplicate relationships will share the same name. This results in a single role-playing dimension in the cube, rather than two very similar dimensions, reducing complexity
If another role playing dimension matching yours does not exist, simply type a relevant name to match your new relationship purpose.
Many-to-many relationships
Many-to-Many Relationships (M2M) enable entities to relate with each other (where one entity contains a parent instance with many children in the relating entity and vice versa).
Note
A customer may have several bank accounts but one bank account may have more than one owner. In order to relate these entities to each other, a table is used in which the primary keys of each entity combine to form a new composite key in a new table.
Key components
Entities that have relationships are normally either Dimensions or Facts. A Many-to-Many Relationship uses a Bridge to link a number of keys together.
Fact | A table that contains one or more measurable columns and many transactions e.g. Bank Account Transactions. |
|---|---|
Dimension | A table key to uniquely identify each entity and additional text columns to describe the entity. |
Bridge | The link, join, or reference table used to hold a combination of keys (one from each dimension) to form the bridge between the relating dimensions. The bridge can then be used to relate a fact table to dimensions (at a different granularity) through it. |