Cloud release notes February 2022
Release number: K54
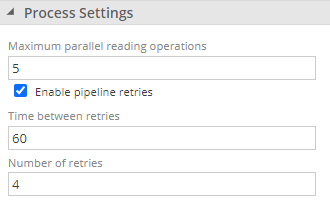
Pipeline retries during model processing
Pipeline retries during model processing of up to 4 times have been introduced. When a model designer or administrator wishes for a model process to retry pipelines during processing, instead of failing immediately after the first failed attempt, this setting can now be configured in the data source Process Settings.
 |
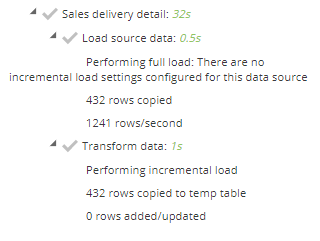
Additional information on the processing tree
Additional information has been added to the model process tree. For every pipeline its possible to see the rows copied, rows per second and Incremental load setting (with a reason for a full load) for the source data, as well as the transform data. "Synchronized reporting calculations" now shows under the "Process cube" node.
 |
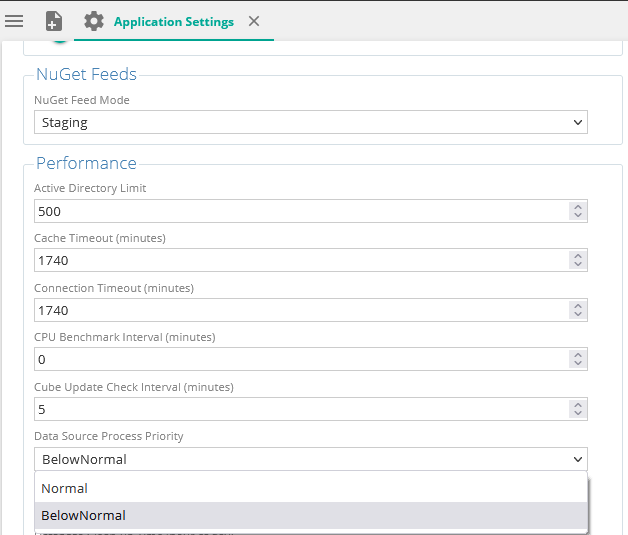
Data source processing priority setting
A new configuration setting has been added for data source processing priority. The setting has two values: "Normal" and "Below normal" . The new default setting of "Below normal" will create data source processes with reduced cpu priority, to avoid UI instability.
It can be changed back to normal which was the default setting in the past.
Important
This setting can only be changed by a support user.
 |
Performance Enhancements
Every release contains performance enhancements and bug fixes to improve Data Hub.
Date of publication 21 February 2022