Sage 100
Sage 100 is offered in 3 editions:
Standard and Advanced use the ProvideX file system to store the information. A 64bit ODBC driver is provided with Sage 100 to connect to ProvideX.
Enterprise uses SQL Server.
Connecting to the data source
Platform Type: ODBC
 |
Important
Prerequisites before using ODBC in Data Hub:
The Sage ODBC driver has to be installed on the Sage100 Server. During installation, the Data Directory (required on the Data Hub connection) will be setup.
Create and install a data gateway on the same server where the Sage 100 Data Directory is.
Data Gateway: Select the data gateway installed on the Sage 100 Server or where the ODBC connection as been created.
Platform Type: choose ODBC
User Name - Specify the user name to login. This can be the same user used to login to the Sage100.
Note
Permissions: The user needed to login form Data Hub, need to be created in Sage100 first with relevant permissions, before connecting to ODBC. The user that deploys the Sage solution or create a model need to have permission to all companies in Sage 100.
Password: Specify the relevant password
Data Directory: The data directory where the ProvideX file system is stored. This directory is configured during the ODBC connection setup.
Platform Type: SQL Server
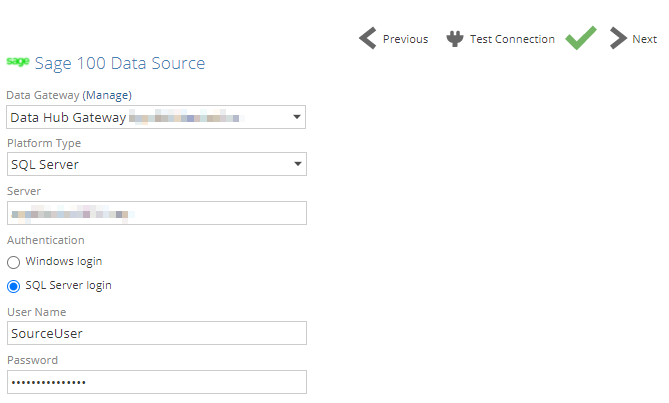 |
Data Gateway: Select the data gateway installed on the Sage 100 Server, or a network location with access to the Sage 100 server.
Platform Type: choose SQL Server
Server - The name of the SQL Server instance hosting the Sage 100 database you want to access. If the server hosts multiple instances, use the syntax ServerName\InstanceName.
Authentication - You can provide credentials to authenticate to the SQL Server instance hosting the Sage 100 database (specified above) in two ways. The method used will depend on how your SQL Server instance is configured:
Windows login - Enter a Windows user name and password.
SQL Server login - Enter a SQL Server user name and password.
Note
Permissions: The SQL user needs read access (+ view database state) to the MAS_system database and the individual company databases. It also needs permission to all companies in Sage 100.
User Name - Type a user name in the same form you use to log in directly to Windows or SQL Server (depending on which authentication method you chose above). This may be just a user name, or it may include the domain name in canonical form (domain\user) or UPN form (user@fully-qualified_domain_name), depending on your environment.
Password: Specify the relevant password
Database - Type the Sage database name to use as the data source, or select the Sage 300 database from a drop-down list of databases found on the specified SQL Server instance.
Advanced settings
One or more optional advanced connection settings can be added or modified for this data source using either of the following:
Advanced panel on the Connect screen when adding the data source.
Properties panel when viewing an existing data source, under the Advanced section.
Troubleshooting
This section aims to provide information about the Data Hub connector for Sage 100 as it relates to resilience of connections.
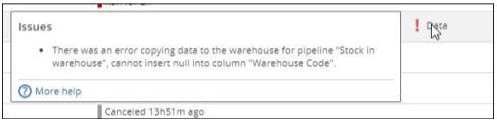
Key integrity errors caused by NULL values
You receive an error message at processing time reporting "cannot insert null into column [...]" when migrating source data in the warehouse
 |
This issue have manifested at a few customer sites when NULL values were found in columns that were part of Pipeline keys. In most cases, those NULL values should not have existed in the source as the columns were also keys in the source “tables”.
According to Sage Support, the Sage 100 application does not insert NULL values, the only possible scenario for such erroneous data is a partner add-on/customization or a user customization that either inserted or imported NULL values.
The data integrity issues applied to:
Customer – NULL values in the AR Division No column, instead of the default value of “00” when a division is not specified in Sage 100
Vendor – NULL values in the Division column, instead of the value 00
Item Transaction History – NULL values in the Stock location code column instead of the value 000
Sales Order History Detail – NULL values in column Sales order no
Accounts receivable – NULL values in column AR Division No
Accounts payable – NULL values in column AP Division No
Inventory – NULL values in Stock location code
To maintain data integrity in our solution and ensure the tables of the data warehouse can be properly indexed, the resolution has been and is to filter the NULLs out in those pipelines. Only columns included in keys have been filtered out. Any similar issue should be reported back to ZAP and the customer’s partner as a partner may also be able to fix the source data issues by running a Sage 100 data integrity tool.
Source migration is stuck refreshing a pipeline, and eventually times out
It takes a long time to process a source table
The rows copied indicator does not update even if the source table appears to still be processing.
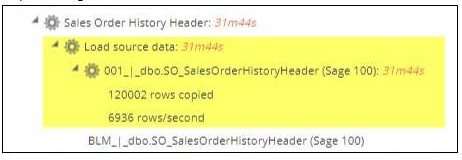
Upon review of the processing logs, there are several query cancellations and retries.
This issue is caused by a crash of the Sage 100 ODBC 64bit driver and occurs when a single SQL query to the datasource returns a result set that is too large, in rows and/or size. The ODBC driver cannot handle this well, coming from even a local ZAP data gateway. It was experienced when processing the following pipelines:
Customer, when the size of the AR_Customer ODBC file was in excess of 1.8GB
SO_SalesOrderHistoryHeader
Sales order lines when the number of rows in the SO_SalesOrderHistoryDetail file was more than 50 million.
To work around this issue, ZAP released an update to the Sage 100 connector that introduced new ways of loading data by issuing multiple queries to the datasource that returns a subset of the data that the ODBC driver can then handle, or in other words “partitioning”.
The following new options have been introduced along with new loading behavior for Sage 100:
A default new loading behavior
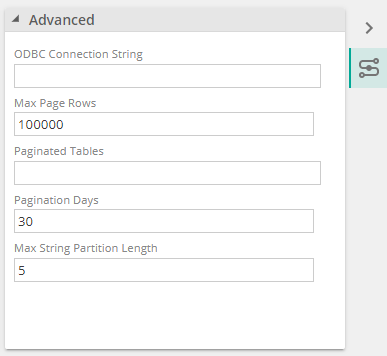
4 new options have been added in the Advanced section of the datasource, namely:
Max Page rows: the maximum number of rows to read before changing a table’s read pagination strategy
Paginated Tables: a comma-separated list of source table names (without schema) to use data pagination on. Leave empty to use default loading strategies.
Pagination Days: Rane of days to days to include in date pagination queries
String Partition Length: Number of suffix characters to partition string pagination columns on
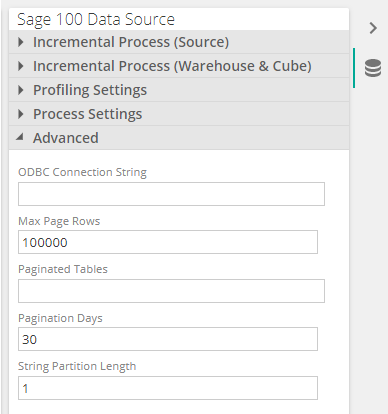
A data model designer can review these settings in the event a source table errors when source migration times out, after retrying several times.
To better understand the behavior and how to interpret the errors and configure the settings, please read the following section.
The loading behavior with the default setting values, as per the above screenshot, is as follows:
For every source table other than: SO_SalesOrderHistoryHeader, SO_SalesOrderHistoryHeader, AR_InvoiceHistoryDetail and AR_Customer, the standard Data Hub data loading applies. We will refer to those tables (which ZAP can review and extend at any time) as String paginated tables.
Those three specific tables are loaded in the following way:
String partitioning is used for full refreshes
String partitioning is also used for loading deltas in an incremental loading scenario
When a source table name is manually added in the Paginated Tables input text box, then the following loading behavior applies:
Paginated queries have a max page size as defined by the Max Page Rows setting which defaults to 100K rows. Hitting this limit would fall back to the next loading strategy or error if there are no more.
For every other source table than the String paginated tables, data loading is performed by executing multiple queries using a data range, as specified in Pagination Days. This loading behavior only applies if the source table includes a CreatedDateTime column and/or a CreatedDate and a CreatedTime columns.
Date pagination is programmatically changing to reduce the range before falling back to string pagination. We would only use string pagination if the date was NULL or down to a single day.
A fully load migration of the String paginated tables use both the pagination and date pagination strategies apply, and follow the following rules:
Date pagination falls back to string pagination if a page read fails. After reading that date range using string pagination, the next page goes back to date pagination and reduce the range back to the Pagination Days setting.
The String pagination logic changes so that it always starts with a suffix length of 1 and then increases if the page is too large (therefore further partitioning data) but only up to the String Partition Length.
Date pagination will change the range back to the setting if the last page read has at least 1 row, and only String pagination would be is used if a value in the CreatedDateTime is NULL.
Date pagination is changing to reduce the range before falling back to string pagination.
Paginated queries time out if reading a row hangs for 1 min, and 2 more attempts are then performed for that same page before falling back to the next pagination strategy. The migration then fails with a friendly error, and a model designer would have to review the logs and default settings to optimize partitioning.
Depending on the column being used for date pagination, pagination may or may not be used for incremental refreshes.